[TOC]
machine learning for credit scoring
一个信用评分案例看机器学习建模基本过程
Banks play a crucial role in market economies. They decide who can get finance and on what terms and can make or break investment decisions. For markets and society to function, individuals and companies need access to credit.
Credit scoring algorithms, which make a guess at the probability of default, are the method banks use to determine whether or not a loan should be granted. This competition requires participants to improve on the state of the art in credit scoring, by predicting the probability that somebody will experience financial distress in the next two years. Dataset
Attribute Information:
| Variable Name | Description | Type |
|---|---|---|
| SeriousDlqin2yrs | Person experienced 90 days past due delinquency or worse | Y/N |
| RevolvingUtilizationOfUnsecuredLines | Total balance on credit divided by the sum of credit limits | percentage |
| age | Age of borrower in years | integer |
| NumberOfTime30-59DaysPastDueNotWorse | Number of times borrower has been 30-59 days past due | integer |
| DebtRatio | Monthly debt payments | percentage |
| MonthlyIncome | Monthly income | real |
| NumberOfOpenCreditLinesAndLoans | Number of Open loans | integer |
| NumberOfTimes90DaysLate | Number of times borrower has been 90 days or more past due. | integer |
| NumberRealEstateLoansOrLines | Number of mortgage and real estate loans | integer |
| NumberOfTime60-89DaysPastDueNotWorse | Number of times borrower has been 60-89 days past due | integer |
| NumberOfDependents | Number of dependents in family | integer |
Read the data into Pandas 将数据读进pandas
1 | import pandas as pd |
| SeriousDlqin2yrs | RevolvingUtilizationOfUnsecuredLines | age | NumberOfTime30-59DaysPastDueNotWorse | DebtRatio | MonthlyIncome | NumberOfOpenCreditLinesAndLoans | NumberOfTimes90DaysLate | NumberRealEstateLoansOrLines | NumberOfTime60-89DaysPastDueNotWorse | NumberOfDependents | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.766127 | 45.0 | 2.0 | 0.802982 | 9120.0 | 13.0 | 0.0 | 6.0 | 0.0 | 2.0 |
| 1 | 0 | 0.957151 | 40.0 | 0.0 | 0.121876 | 2600.0 | 4.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 0 | 0.658180 | 38.0 | 1.0 | 0.085113 | 3042.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0 | 0.233810 | 30.0 | 0.0 | 0.036050 | 3300.0 | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0 | 0.907239 | 49.0 | 1.0 | 0.024926 | 63588.0 | 7.0 | 0.0 | 1.0 | 0.0 | 0.0 |
1 | data.shape |
(112915, 11)
去除异常值 Drop na
1 | data.isnull().sum(axis=0) |
SeriousDlqin2yrs 0
RevolvingUtilizationOfUnsecuredLines 0
age 4267
NumberOfTime30-59DaysPastDueNotWorse 0
DebtRatio 0
MonthlyIncome 0
NumberOfOpenCreditLinesAndLoans 0
NumberOfTimes90DaysLate 0
NumberRealEstateLoansOrLines 0
NumberOfTime60-89DaysPastDueNotWorse 0
NumberOfDependents 4267
dtype: int64
1 | data.dropna(inplace=True) |
(108648, 11)
创建X 和 y Create X and y
1 | y = data['SeriousDlqin2yrs'] |
1 | y.mean() |
0.06742876076872101
1 | import seaborn as sns |
1 | sns.countplot(x='SeriousDlqin2yrs',data=data) |
<matplotlib.axes._subplots.AxesSubplot at 0x24081eb9828>
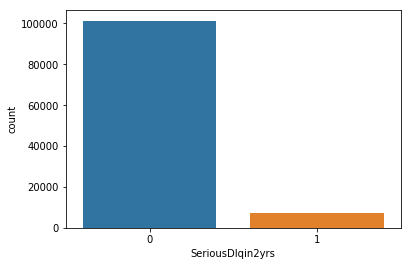
1 | #从样本中可以看出:label为1的样本偏少,可见样本失衡 |
练习1:数据集准备
把数据切分成训练集和测试集
切分数据集
1 | # Added version check for recent scikit-learn 0.18 checks |
对连续值特征做幅度缩放
1 | from sklearn.preprocessing import StandardScaler |
练习2
使用logistic regression/决策树/SVM/KNN…等sklearn分类算法进行分类,尝试查sklearn API了解模型参数含义,调整不同的参数。
logistic regression
1 |
|
LogisticRegression(C=1000.0, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l1', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
1 | LogisticRegression(C=1000.0, class_weight=None, dual=False, |
LogisticRegression(C=1000.0, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l1', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
1 | print('训练集准确度:%f'%lr.score(X_train_std,y_train)) |
训练集准确度:0.933126
1 | ##### 逻辑回归模型的系数 |
1 | import numpy as np |
0) NumberOfTime30-59DaysPastDueNotWorse 1.728754
1) NumberOfTimes90DaysLate 1.689046
2) DebtRatio 0.312098
3) NumberOfDependents 0.116383
4) RevolvingUtilizationOfUnsecuredLines -0.014289
5) NumberOfOpenCreditLinesAndLoans -0.091911
6) MonthlyIncome -0.115234
7) NumberRealEstateLoansOrLines -0.196422
8) age -0.364305
9) NumberOfTime60-89DaysPastDueNotWorse -3.247876
1 | #我的理解是权重绝对值大的特征标签比较重要 |
1 | #### 决策树 |
1 | from sklearn.tree import DecisionTreeClassifier |
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=0,
splitter='best')
1 | DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=3, |
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=1e-07,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=0,
splitter='best')
1 | print('训练集准确度:%f'%tree.score(X_train_std,y_train)) |
训练集准确度:0.934217
SVM(支持向量机)
太耗时间了,只取了“NumberOfTime60-89DaysPastDueNotWorse”这一项特征标签
1 | X_train_std=pd.DataFrame(X_train_std,columns=feat_labels) |
| NumberOfTime60-89DaysPastDueNotWorse | |
|---|---|
| 0 | -0.054381 |
| 1 | -0.054381 |
| 2 | -0.054381 |
| 3 | -0.054381 |
| 4 | -0.054381 |
1 | from sklearn.svm import SVC |
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
1 | SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, |
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
1 | print('训练集准确度:%f'%svm.score(X_train_std[['NumberOfTime60-89DaysPastDueNotWorse']],y_train)) |
训练集准确度:0.932876
KNN
1 | from sklearn.neighbors import KNeighborsClassifier |
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
练习3
在测试集上进行预测,计算准确度
logistic regression
1 | y_pred_lr=lr.predict(X_test) |
错误分类数: 2171
测试集准确度:0.933886
决策树
1 | y_pred_tree=tree.predict(X_test) |
错误分类数: 2498
测试集准确度:0.935021
SVM
1 | y_pred_svm=svm.predict(X_test[['DebtRatio']]) |
错误分类数: 4619
测试集准确度:0.934100
KNN
1 | y_pred_knn=knn.predict(X_test) |
错误分类数: 2213
测试集准确度:0.932106
练习4
查看sklearn的官方说明,了解分类问题的评估标准,并对此例进行评估。
y的类别
1 | class_names=np.unique(data['SeriousDlqin2yrs'].values) |
array([0, 1], dtype=int64)
4种方法的confusion matrix
1 |
|
array([[30424, 0],
[ 2171, 0]], dtype=int64)
1 | cnf_matrix_tree=confusion_matrix(y_test, y_pred_tree) |
array([[29346, 1078],
[ 1420, 751]], dtype=int64)
1 | cnf_matrix_svm=confusion_matrix(y_test, y_pred_svm) |
array([[27661, 2763],
[ 1856, 315]], dtype=int64)
1 | cnf_matrix_knn=confusion_matrix(y_test, y_pred_knn) |
array([[30351, 73],
[ 2140, 31]], dtype=int64)
一个绘制混淆矩阵的函数
1 | import itertools |
可视化
以logistic regression 为例
1 | np.set_printoptions(precision=2) |
Confusion matrix, without normalization
[[30424 0]
[ 2171 0]]
Normalized confusion matrix
[[1. 0.]
[1. 0.]]
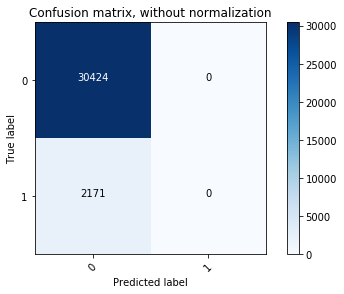
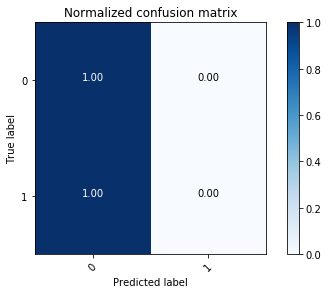
1 | #可见,真实标签为“0”的分类准确率很高。 |
练习5
银行通常会有更严格的要求,因为fraud带来的后果通常比较严重,一般我们会调整模型的标准。
比如在logistic regression当中,一般我们的概率判定边界为0.5,但是我们可以把阈值设定低一些,来提高模型的“敏感度”,试试看把阈值设定为0.3,再看看这时的评估指标(主要是准确率和召回率)。
tips:sklearn的很多分类模型,predict_prob可以拿到预估的概率,可以根据它和设定的阈值大小去判断最终结果(分类类别)
1 | from sklearn.linear_model import LogisticRegression |
LogisticRegression(C=1000.0, class_weight={1: 0.3, 0: 0.7}, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
1 | y_pred_lr=lr.predict(X_test) |
错误分类数: 2169
训练集准确度:0.933456
1 | from sklearn.metrics import confusion_matrix |
array([[30410, 14],
[ 2155, 16]], dtype=int64)
练习6:特征选择、重新建模
尝试对不同特征的重要度进行排序,通过特征选择的方式,对特征进行筛选。并重新建模,观察此时的模型准确率等评估指标。
用随机森林的方法进行特征筛选
1 | from sklearn.ensemble import RandomForestClassifier |
1 | import numpy as np |
0) NumberOfDependents 0.188808
1) NumberOfTime60-89DaysPastDueNotWorse 0.173198
2) NumberRealEstateLoansOrLines 0.165334
3) NumberOfTimes90DaysLate 0.122311
4) NumberOfOpenCreditLinesAndLoans 0.089278
5) MonthlyIncome 0.087939
6) DebtRatio 0.051493
7) NumberOfTime30-59DaysPastDueNotWorse 0.045888
8) age 0.043824
9) RevolvingUtilizationOfUnsecuredLines 0.031928
选取4个特征,建立逻辑回归模型
1 | X_train_4feat=X_train_std[['NumberOfDependents','NumberOfTime60-89DaysPastDueNotWorse','NumberRealEstateLoansOrLines','NumberOfTimes90DaysLate']] |
1 | from sklearn.linear_model import LogisticRegression |
1 | LogisticRegression(C=1000.0, class_weight=None, dual=False, |
1 | print('训练集准确度:%f'%lr.score(X_train_4feat,y_train)) |
训练集准确度:0.933086
1 | y_pred_lr=lr.predict(X_test_4feat) |
错误分类数: 2161
测试集准确度:0.933701
1 | cnf_matrix_lr=confusion_matrix(y_test, y_pred_lr) |
array([[30381, 43],
[ 2118, 53]])
从最后的结果看,虽然经过特征选择和模型参数调整,但依然未能解决混淆矩阵指标太差的问题。
1 | 一个完整机器学习项目流程总结 |

