0.学习目标
了解下我们为什么要学习JVM优化
掌握jvm的运行参数以及参数的设置
掌握jvm的内存模型(堆内存)
掌握jamp命令的使用以及通过MAT工具进行分析
掌握定位分析内存溢出的方法
掌握jstack命令的使用
掌握VisualJVM工具的使用
1、我们为什么要对jvm做优化?
在本地开发环境中我们很少会遇到需要对jvm进行优化的需求,但是到了生产环境,我们 可能将有下面的需求:
运行的应用“卡住了”,日志不输出,程序没有反应
服务器的CPU负载突然升高 在多线程应用下,如何分配线程的数量?
……
我们将对jvm有更深入的学习,我们不仅要让程序能跑起来,而且是可以 跑的更快!可以分析解决在生产环境中所遇到的各种“棘手”的问题。
2、jvm的运行参数
在jvm中有很多的参数可以进行设置,这样可以让jvm在各种环境中都能够高效的运行。 绝大部分的参数保持默认即可。
2.1、三种参数类型
jvm的参数类型分为三类,分别是:
标准参数
- -help
- -version
-X参数 (非标准参数)
- -Xint
- -Xcomp
-XX参数(使用率较高)
- -XX:newSize
- -XX:+UseSerialGC
2.2、标准参数
jvm的标准参数,一般都是很稳定的,在未来的JVM版本中不会改变,可以使用java -help检索出所有的标准参数。
1 | [root@node01 ~]# java ‐help |
2.2.1、实战
实战1:查看jvm版本
1 | [root@node01 ~]# java ‐version |
实战2:通过-D设置系统属性参数
1 | public class TestJVM { |
进行编译、测试:
1 | #编译 |
2.2.2、-server与-client参数
可以通过-server或-client设置jvm的运行参数。
- 它们的区别是Server VM的初始堆空间会大一些,默认使用的是并行垃圾回收器,启动慢运行快。
- Client VM相对来讲会保守一些,初始堆空间会小一些,使用串行的垃圾回收器,它的目标是为了让JVM的启动速度更快,但运行速度会比Serverm模式慢些。
- JVM在启动的时候会根据硬件和操作系统自动选择使用Server还是Client类型的 JVM。
- 32位操作系统
- 如果是Windows系统,不论硬件配置如何,都默认使用Client类型的JVM。
- 如果是其他操作系统上,机器配置有2GB以上的内存同时有2个以上CPU的话默认使用server模式,否则使用client模式。
- 64位操作系统
- 只有server类型,不支持client类型。
测试:
1 | [root@node01 test]# java ‐client ‐showversion TestJVM |
2.3、-X参数
jvm的-X参数是非标准参数,在不同版本的jvm中,参数可能会有所不同,可以通过java - X查看非标准参数。
1 | [root@node01 test]# java ‐X |
2.3.1、-Xint、-Xcomp、-Xmixed
- 在解释模式(interpreted mode)下,-Xint标记会强制JVM执行所有的字节码,当然这会降低运行速度,通常低10倍或更多。
- -Xcomp参数与它(-Xint)正好相反,JVM在第一次使用时会把所有的字节码编译成本地代码,从而带来最大程度的优化。
- 然而,很多应用在使用-Xcomp也会有一些性能损失,当然这比使用-Xint损失的少,原因是— xcomp没有让JVM启用JIT编译器的全部功能。JIT编译器可以对是否需要编译做判断,如果所有代码都进行编译的话,对于一些只执行一次的代码就
没有意义了。
- 然而,很多应用在使用-Xcomp也会有一些性能损失,当然这比使用-Xint损失的少,原因是— xcomp没有让JVM启用JIT编译器的全部功能。JIT编译器可以对是否需要编译做判断,如果所有代码都进行编译的话,对于一些只执行一次的代码就
- -Xmixed是混合模式,将解释模式与编译模式进行混合使用,由jvm自己决定,这是jvm默认的模式,也是推荐使用的模式。
示例:强制设置运行模式
1 | #强制设置为解释模式 |
2.4、-XX参数
-XX参数也是非标准参数,主要用于jvm的调优和debug操作。
-XX参数的使用有2种方式,一种是boolean类型,一种是非boolean类型: boolean类型
格式:-XX:[±]
如:-XX:+DisableExplicitGC 表示禁用手动调用gc操作,也就是说调用
System.gc()无效
非boolean类型格式:-XX:
如:-XX:NewRatio=1 表示新生代和老年代的比值
用法:
1 | [root@node01 test]# java ‐showversion ‐XX:+DisableExplicitGC TestJVM |
2.5、-Xms与-Xmx参数
Xms与-Xmx分别是设置jvm的堆内存的初始大小和最大大小。
-Xmx2048m:等价于-XX:MaxHeapSize,设置JVM最大堆内存为2048M。
-Xms512m:等价于-XX:InitialHeapSize,设置JVM初始堆内存为512M。适当的调整jvm的内存大小,可以充分利用服务器资源,让程序跑的更快。示例:[root@node01 test]# java ‐Xms512m ‐Xmx2048m TestJVM itcast
1 | [root@node01 test]# java ‐Xms512m ‐Xmx2048m TestJVM |
2.6、查看jvm的运行参数
有些时候我们需要查看jvm的运行参数,这个需求可能会存在2种情况:
第一,运行java命令时打印出运行参数;
第二,查看正在运行的java进程的参数;
2.6.1、运行java命令时打印参数
运行java命令时打印参数,需要添加-XX:+PrintFlagsFinal参数即可。
1 | [root@node01 test]# java ‐XX:+PrintFlagsFinal ‐version [Global flags] |
由上述的信息可以看出,参数有boolean类型和数字类型,值的操作符是=或:=,分别代 表默认值和被修改的值。
示例:
1 | java ‐XX:+PrintFlagsFinal ‐XX:+VerifySharedSpaces ‐version |
2.6.2、查看正在运行的jvm参数
如果想要查看正在运行的jvm就需要借助于jinfo命令查看。
首先,启动一个tomcat用于测试,来观察下运行的jvm参数。
1 | cd /tmp/ |
访问成功:
1 | #查看所有的参数,用法:jinfo ‐flags <进程id> |
3、jvm的内存模型
jvm的内存模型在1.7和1.8有较大的区别,虽然本套课程是以1.8为例进行讲解,但是我们 也是需要对1.7的内存模型有所了解,所以接下里,我们将先学习1.7再学习1.8的内存模 型。
3.1、jdk1.7的堆内存模型
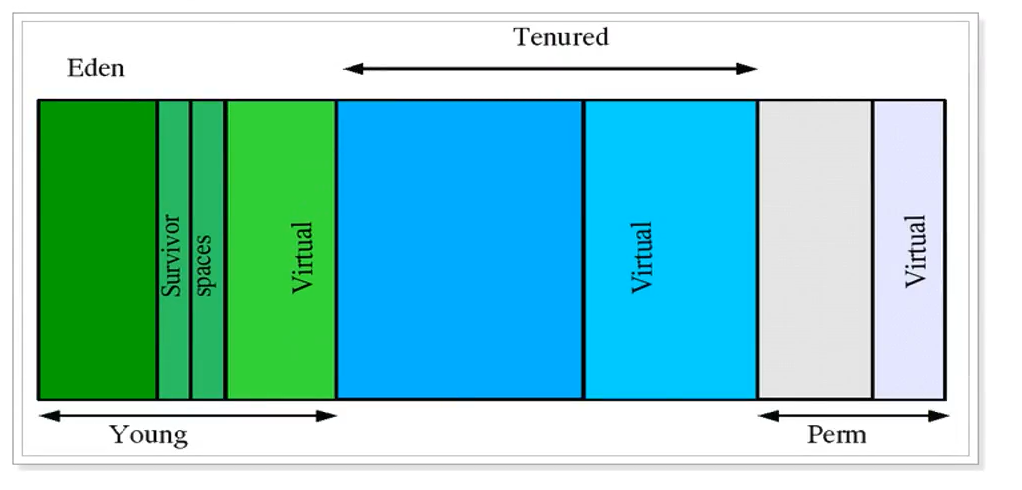
- Young 年轻区(代)
Young区被划分为三部分,Eden区和两个大小严格相同的Survivor区,其中, Survivor区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制 对象用,在Eden区间变满的时候, GC就会将存活的对象移到空闲的Survivor区间中,根据JVM的策略,在经过几次垃圾收集后,任然存活于Survivor的对象将被移动到Tenured区间。 - Tenured 年老区
Tenured区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在Young 复制转移一定的次数以后,对象就会被转移到Tenured区,一般如果系统中用了application级别的缓存,缓存中的对象往往会被转移到这一区间。 - Perm 永久区
Perm代主要保存class,method,filed对象,这部份的空间一般不会溢出,除非一次性 加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的class没有被卸载掉,这样就造 成了大量的class对象保存在了perm中,这种情况下,一般重新启动应用服务器可以 解决问题。 - Virtual区:
- 最大内存和初始内存的差值,就是Virtual区。
3.2、jdk1.8的堆内存模型
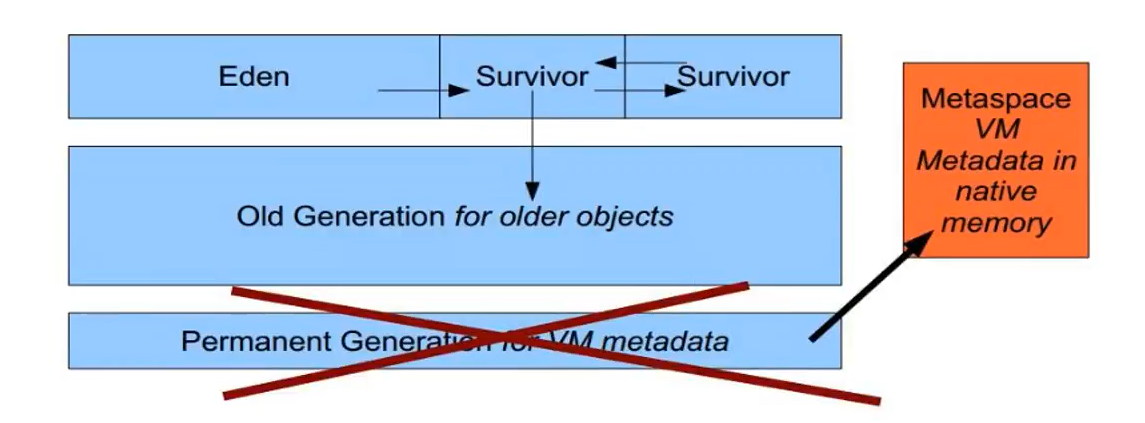
由上图可以看出,jdk1.8的内存模型是由2部分组成,年轻代 + 年老代。
年轻代:Eden + 2*Survivor
年老代:OldGen
在jdk1.8中变化最大的Perm区,用Metaspace(元数据空间)进行了替换。
需要特别说明的是:Metaspace所占用的内存空间不是在虚拟机内部,而是在本地内存 空间中,这也是与1.7的永久代最大的区别所在。
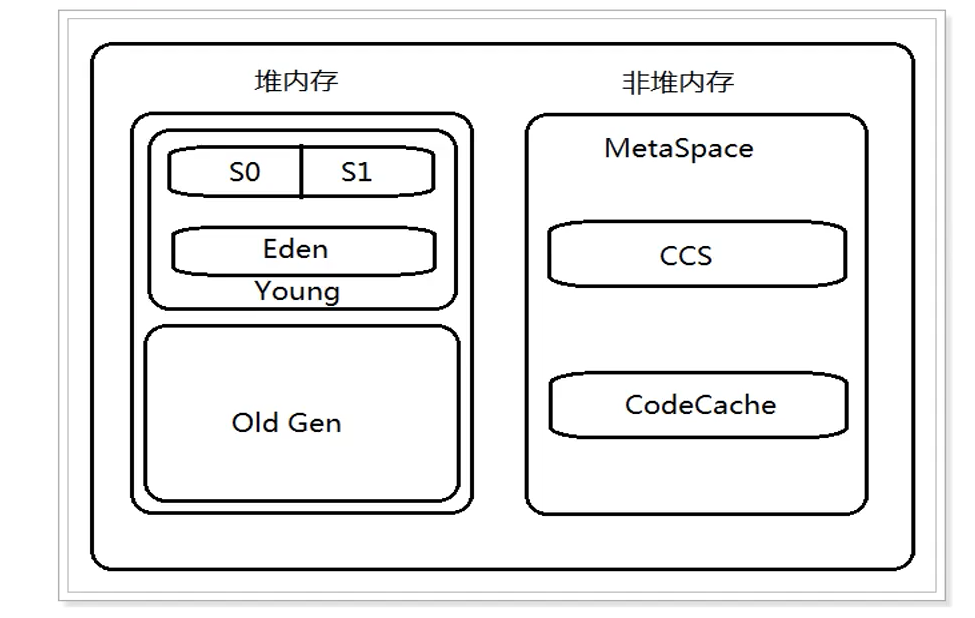
其中:CodeCache存放的是一些类和class。CCS代表的是一些压缩指针。
3.3、为什么要废弃1.7中的永久区?
官网给出了解释:http://openjdk.java.net/jeps/122
1 | This is part of the JRockit and Hotspot convergence effort. JRockit |
现实使用中,由于永久代内存经常不够用或发生内存泄露,爆出异常
java.lang.OutOfMemoryError: PermGen。
基于此,将永久区废弃,而改用元空间,改为了使用本地内存空间。
3.4、通过jstat命令进行查看堆内存使用情况
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。命令的格式如下: jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数]
3.4.1、查看class加载统计
1 | [root@node01 ~]# jps |
说明:
Loaded:加载class的数量
Bytes:所占用空间大小
Unloaded:未加载数量
Bytes:未加载占用空间
Time:时间
3.4.2、查看编译统计
1 | [root@node01 ~]# jstat ‐compiler 6219 |
说明:
Compiled:编译数量。
Failed:失败数量
Invalid:不可用数量
Time:时间
FailedType:失败类型
FailedMethod:失败的方法
3.4.3、垃圾回收统计
1 | [root@node01 ~]# jstat ‐gc 6219 |
#也可以指定打印的间隔和次数,每1秒中打印一次,共打印5次
1 | [root@node01 ~]# jstat ‐gc 6219 1000 5 |
说明:
S0C:第一个Survivor区的大小(KB)
S1C:第二个Survivor区的大小(KB)
S0U:第一个Survivor区的使用大小(KB)
S1U:第二个Survivor区的使用大小(KB) EC:Eden区的大小(KB)
EU:Eden区的使用大小(KB)
OC:Old 区 大 小 (KB)
OU:Old 使 用 大 小 (KB)
MC:方法区大小(KB)
MU:方法区使用大小(KB)
CCSC:压缩类空间大小(KB)
CCSU:压缩类空间使用大小(KB)
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
4、jmap的使用以及内存溢出分析
前面通过jstat可以对jvm堆的内存进行统计分析,而jmap可以获取到更加详细的内容, 如:内存使用情况的汇总、对内存溢出的定位与分析。
4.1、查看内存使用情况
1 | [root@# jmap ‐heap 6219 |
4.2、查看内存中对象数量及大小
1 | #查看所有对象,包括活跃以及非活跃的jmap ‐histo <pid> | more |
4.3、将内存使用情况dump到文件中
有些时候我们需要将jvm当前内存中的情况dump到文件中,然后对它进行分析,jmap也 是支持dump到文件中的。
1 | #用法: |

可以看到已经在/tmp下生成了dump.dat的文件。
4.4、通过jhat对dump文件进行分析
在上一小节中,我们将jvm的内存dump到文件中,这个文件是一个二进制的文件,不方 便查看,这时我们可以借助于jhat工具进行查看。
1 | #用法: |
打开浏览器进行访问:http://192.168.40.133:7000/
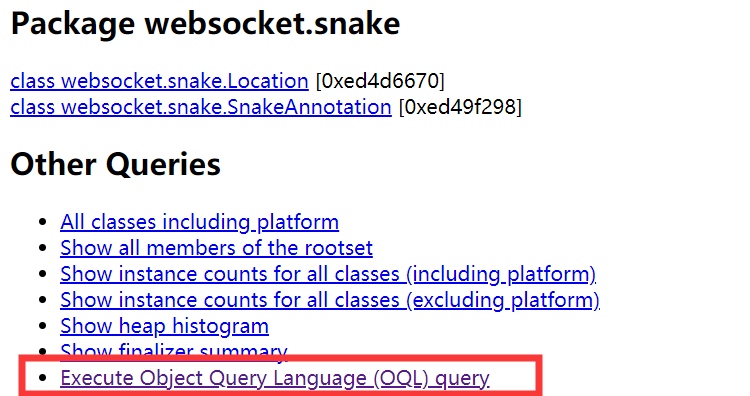
在最后面有OQL查询功能。
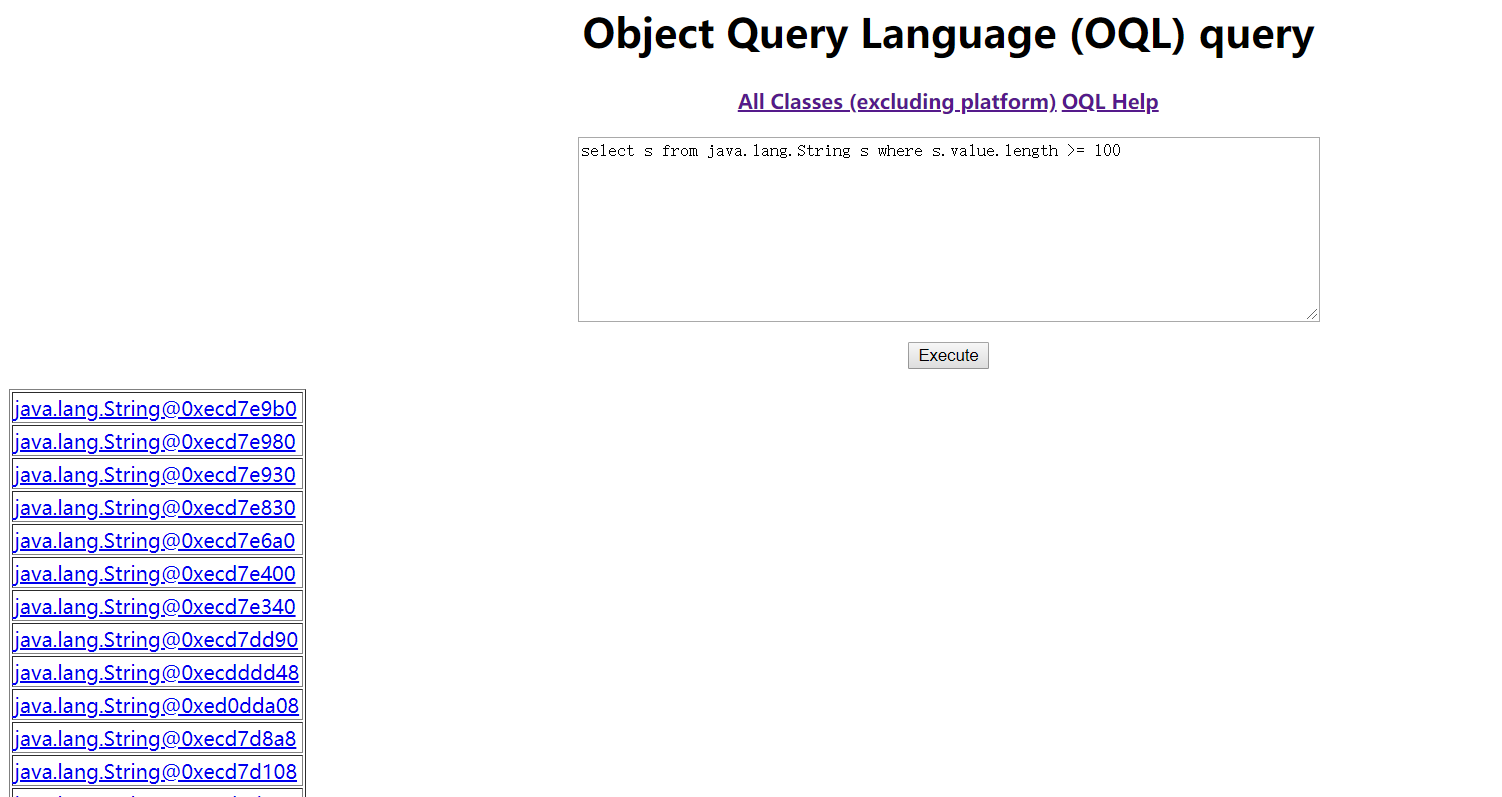
如:查询字符长度大于100的内容。
4.5、通过MAT工具对dump文件进行分析
4.5.1、MAT工具介绍
MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速、功能丰富的JAVA heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止 了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
官网地址:https://www.eclipse.org/mat/
4.5.2、下载安装
下载地址:https://www.eclipse.org/mat/downloads.php
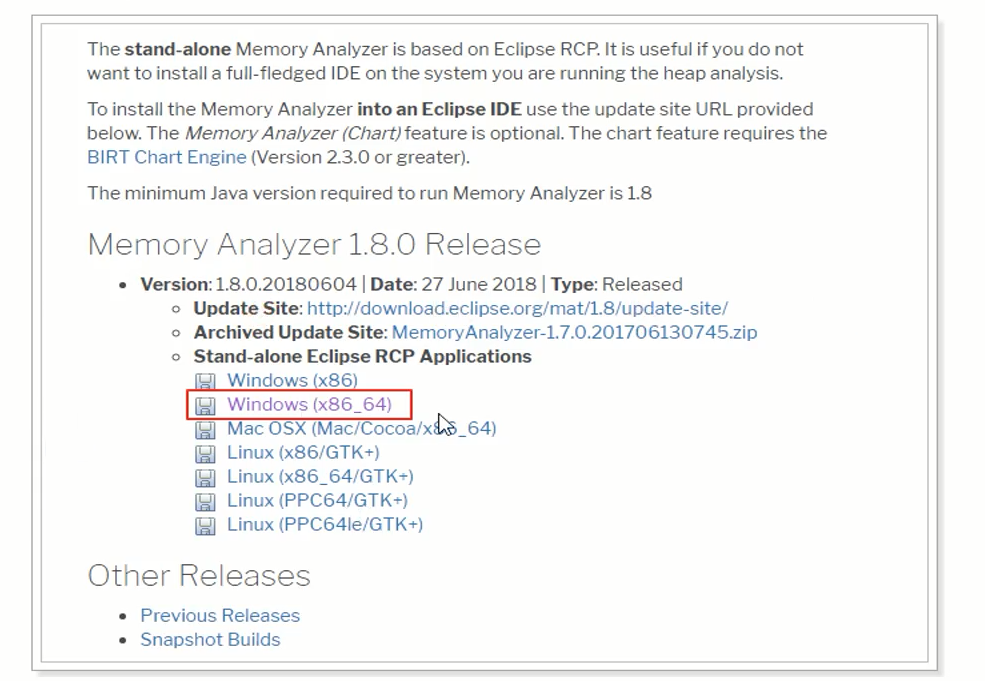
将下载得到的MemoryAnalyzer-1.8.0.20180604-win32.win32.x86_64.zip进行解压

4.5.3、使用
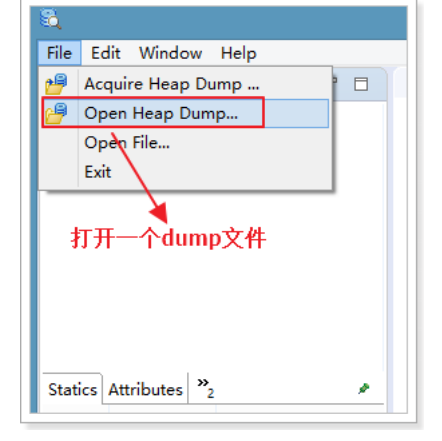
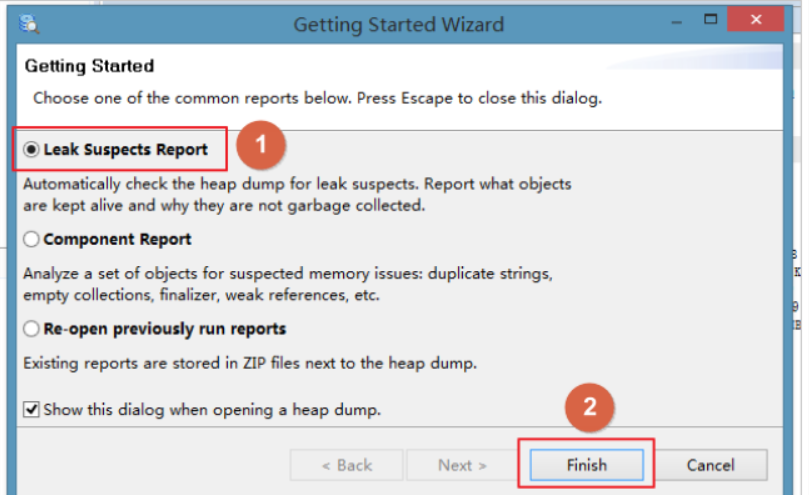
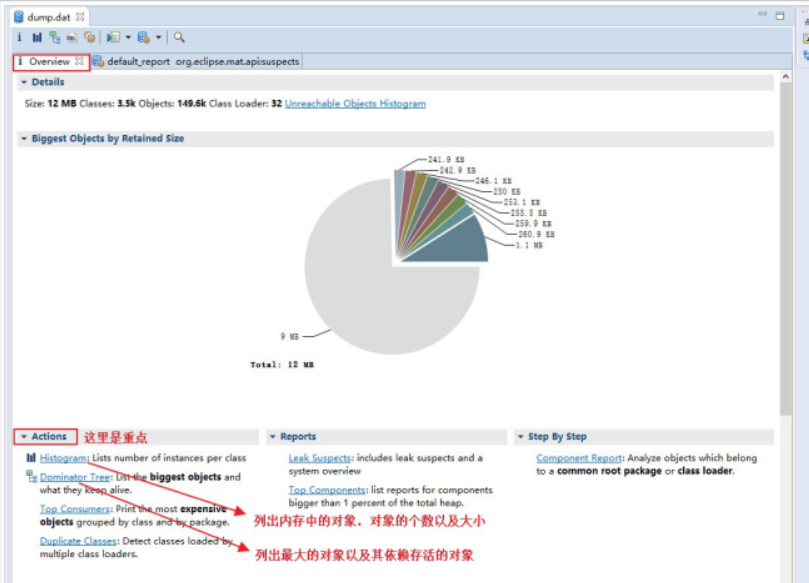
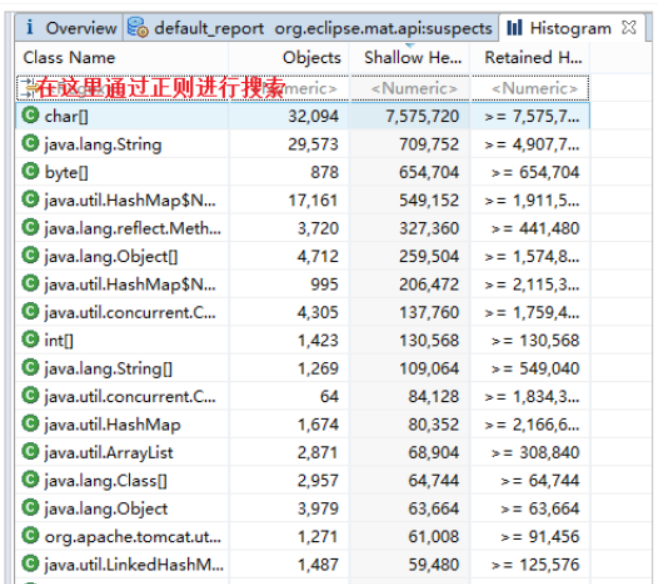
查看对象以及它的依赖:
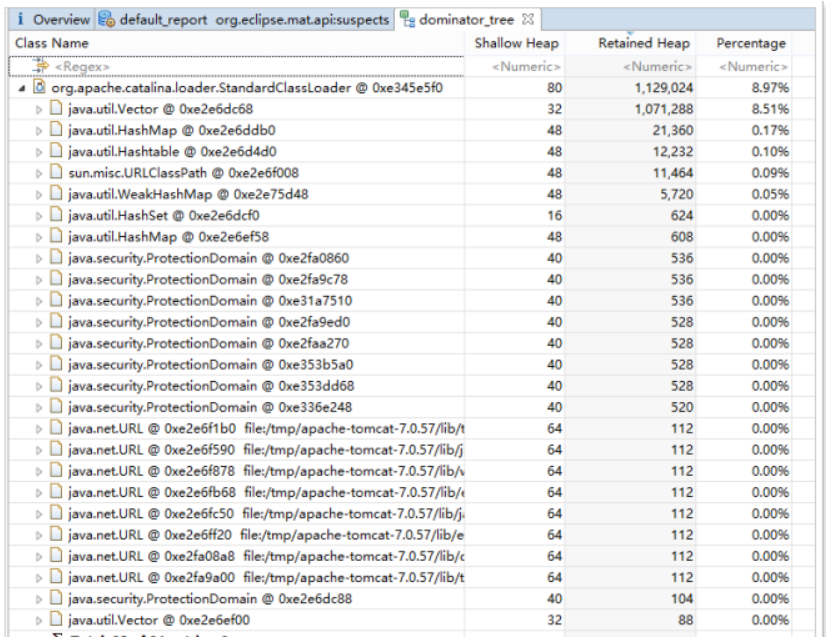
查看可能存在内存泄露 的分析:
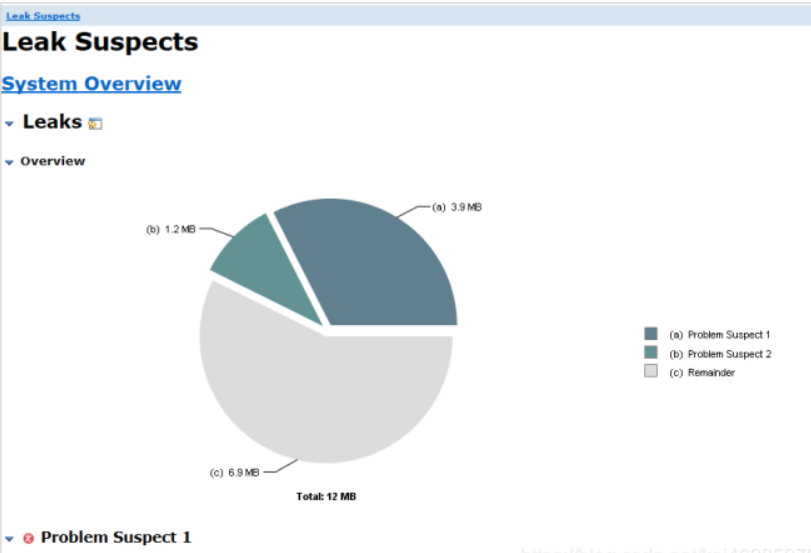
5、实战:内存溢出的定位与分析
内存溢出在实际的生产环境中经常会遇到,比如,不断的将数据写入到一个集合中,出现了死循环,读取超大的文件等等,都可能会造成内存溢出。
如果出现了内存溢出,首先我们需要定位到发生内存溢出的环节,并且进行分析,是正常还是非正常情况,如果是正常的需求,就应该考虑加大内存的设置,如果是非正常需求,那么就要对代码进行修改,修复这个bug。
首先,我们得先学会如何定位问题,然后再进行分析。如何定位问题呢,我们需要借助于jmap与MAT工具进行定位分析。
接下来,我们模拟内存溢出的场景。
5.1、模拟内存溢出
编写代码,向List集合中添加100万个字符串,每个字符串由1000个UUID组成。如果程 序能够正常执行,最后打印ok。
1 | package cn.itcast.jvm; |
为了演示效果,我们将设置执行的参数,这里使用的是Idea编辑器。
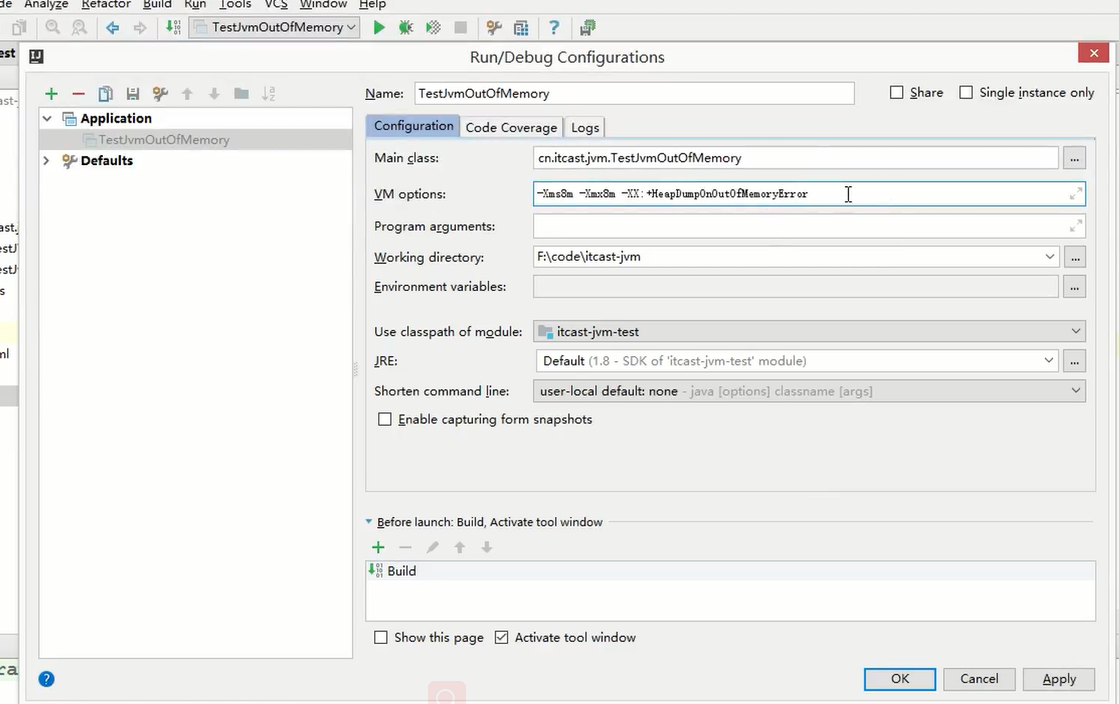
1 | #参数如下: |
5.2、运行测试
测试结果如下:
1 | java.lang.OutOfMemoryError: Java heap space Dumping heap to java_pid5348.hprof ... |
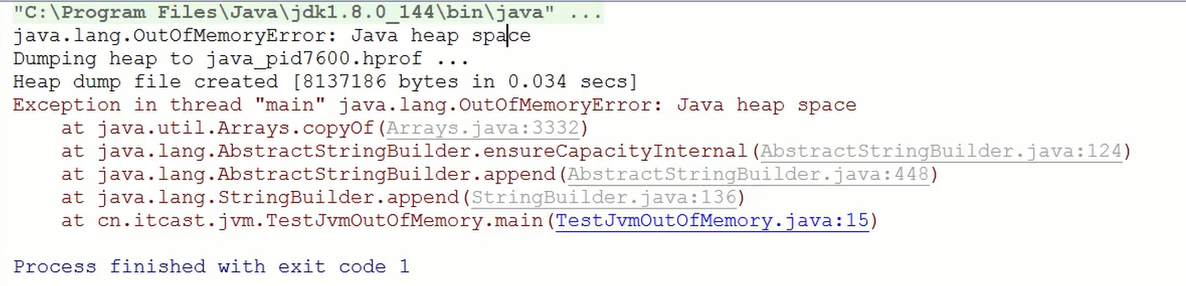
可以看到,当发生内存溢出时,会dump文件到java_pid5348.hprof。
5.3、导入到MAT工具中进行分析
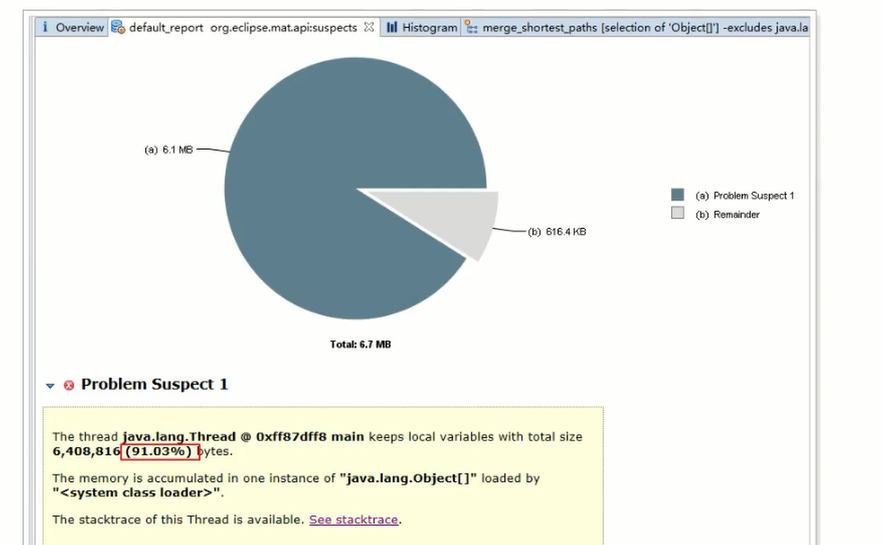
可以看到,有91.03%的内存由Object[]数组占有,所以比较可疑。
分析:这个可疑是正确的,因为已经有超过90%的内存都被它占有,这是非常有可能出现内存溢出的。
查看详情:
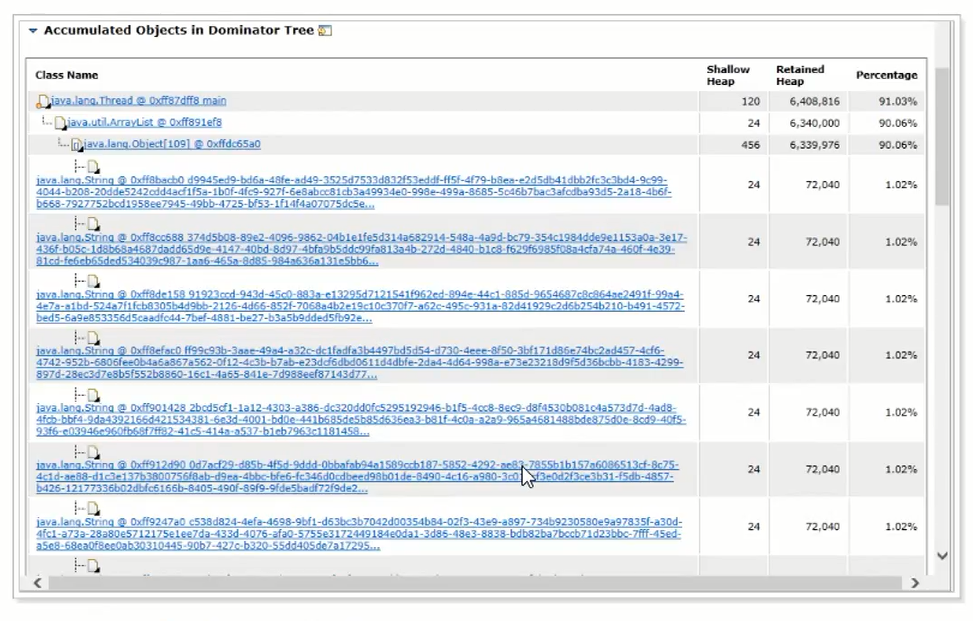
可以看到集合中存储了大量的uuid字符串。
6、jstack的使用
有些时候我们需要查看下jvm中的线程执行情况,比如,发现服务器的CPU的负载突然增高了、出现了死锁、死循环等,我们该如何分析呢?
由于程序是正常运行的,没有任何的输出,从日志方面也看不出什么问题,所以就需要 看下jvm的内部线程的执行情况,然后再进行分析查找出原因。
这个时候,就需要借助于jstack命令了,jstack的作用是将正在运行的jvm的线程情况进 行快照,并且打印出来:
1 | #用法:jstack <pid> |
1 | "VM Thread" os_prio=0 tid=0x00007fabe8073000 nid=0x89f runnable |
6.1、线程的状态
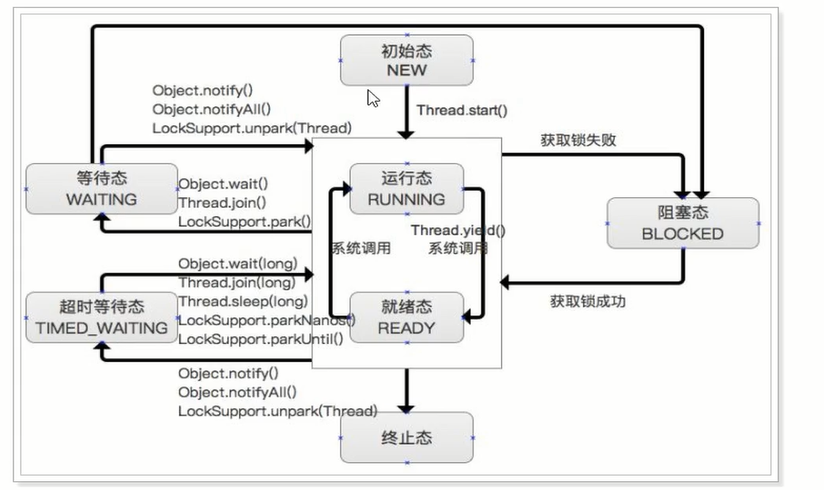
在Java中线程的状态一共被分成6种:
- 初始态(NEW)
创建一个Thread对象,但还未调用start()启动线程时,线程处于初始态。 运行态(RUNNABLE),在Java中,运行态包括 就绪态 和 运行态。
- 就绪态
- 该状态下的线程已经获得执行所需的所有资源,只要CPU分配执行权就能运行。
- 所有就绪态的线程存放在就绪队列中。
- 运行态
- 获得CPU执行权,正在执行的线程。
- 由于一个CPU同一时刻只能执行一条线程,因此每个CPU每个时刻只有一条
运行态的线程。
- 就绪态
阻塞态(BLOCKED)
- 当一条正在执行的线程请求某一资源失败时,就会进入阻塞态。
- 而在Java中,阻塞态专指请求锁失败时进入的状态。
- 由一个阻塞队列存放所有阻塞态的线程。
- 处于阻塞态的线程会不断请求资源,一旦请求成功,就会进入就绪队列,等待执行。
等待态(WAITING)
- 当前线程中调用wait、join、park函数时,当前线程就会进入等待态。
- 也有一个等待队列存放所有等待态的线程。
- 线程处于等待态表示它需要等待其他线程的指示才能继续运行。
- 进入等待态的线程会释放CPU执行权,并释放资源(如:锁)
超时等待态(TIMED_WAITING)
- 当运行中的线程调用sleep(time)、wait、join、parkNanos、parkUntil时,就会进入该状态;
- 它和等待态一样,并不是因为请求不到资源,而是主动进入,并且进入后需要其他线程唤醒;
- 进入该状态后释放CPU执行权 和 占有的资源。
- 与等待态的区别:到了超时时间后自动进入阻塞队列,开始竞争锁。
终止态(TERMINATED)
线程执行结束后的状态。
6.2、实战:死锁问题
如果在生产环境发生了死锁,我们将看到的是部署的程序没有任何反应了,这个时候我 们可以借助jstack进行分析,下面我们实战下查找死锁的原因。
6.2.1、构造死锁
编写代码,启动2个线程,Thread1拿到了obj1锁,准备去拿obj2锁时,obj2已经被Thread2锁定,所以发送了死锁。
1 | package cn.itcast.jvm; |
6.2.2、在linux上运行
1 | [root@node01 test]# javac TestDeadLock.java |
6.2.3、使用jstack进行分析
1 | [root@node01 ~]# jstack 3256 |
在输出的信息中,已经看到,发现了1个死锁,关键看这个:
1 | "Thread‐1": |
可以清晰的看到:
- Thread2获取了 <0x00000000f655dc50> 的锁,等待获取 <0x00000000f655dc40>
这个锁 - Thread1获取了 <0x00000000f655dc40> 的锁,等待获取 <0x00000000f655dc50>
这个锁 - 由此可见,发生了死锁
7、VisualVM工具的使用
VisualVM,能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈(如100个String对象分别由哪几个对象分配出来的)。
VisualVM使用简单,几乎0配置,功能还是比较丰富的,几乎囊括了其它JDK自带命令的所有功能。
- 内存信息线程信息
- Dump堆(本地进程)
- Dump线程(本地进程)
- 打开堆Dump。堆Dump可以用jmap来生成。打开线程Dump
- 生成应用快照(包含内存信息、线程信息等等)
- 性能分析。CPU分析(各个方法调用时间,检查哪些方法耗时多),内存分析(各类对象占用的内存,检查哪些类占用内存多)
- ……
7.1、启动
在jdk的安装目录的bin目录下,找到jvisualvm.exe,双击打开即可。
7.2、查看本地进程
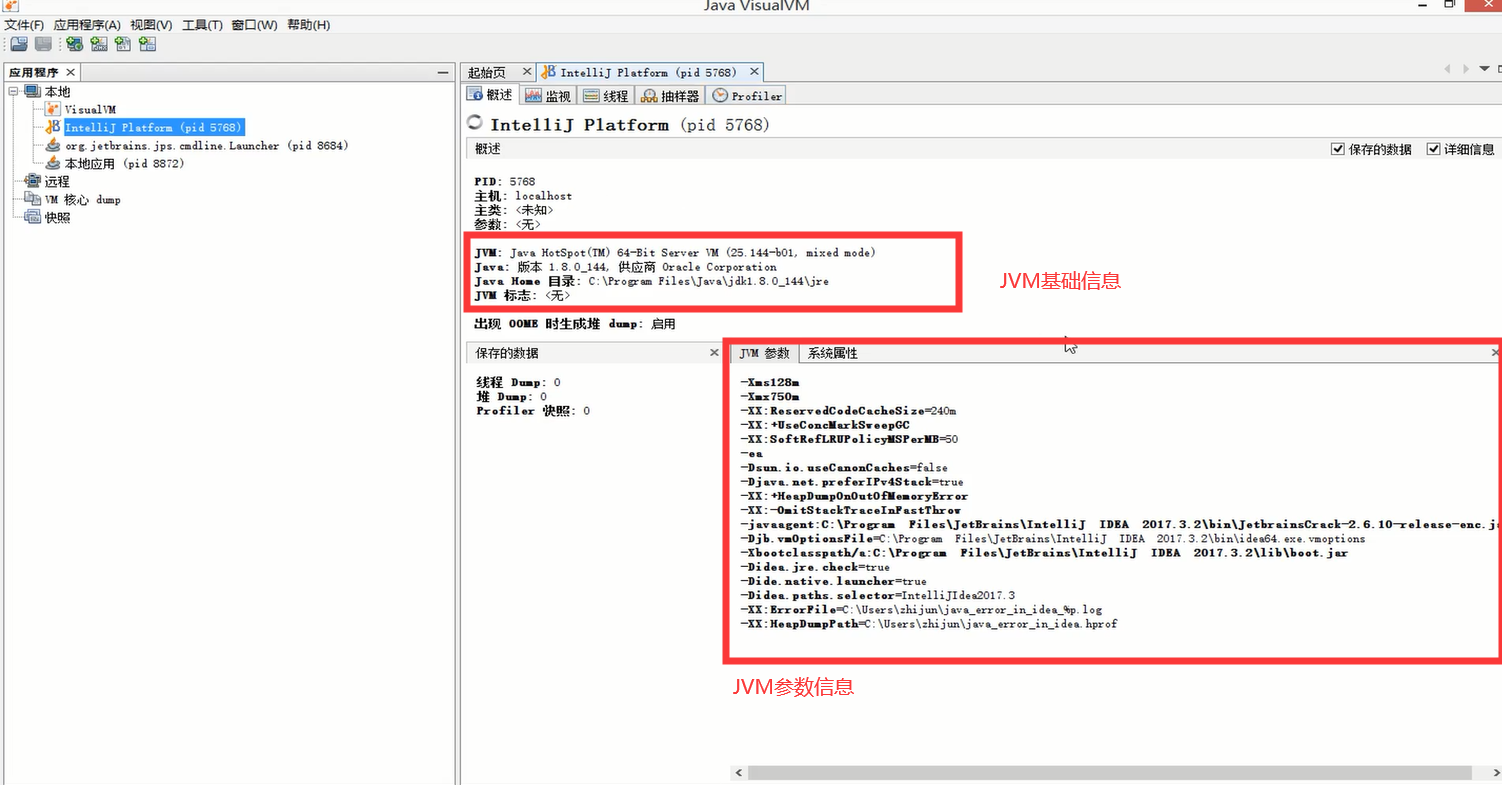
7.3、查看CPU、内存、类、线程运行信息
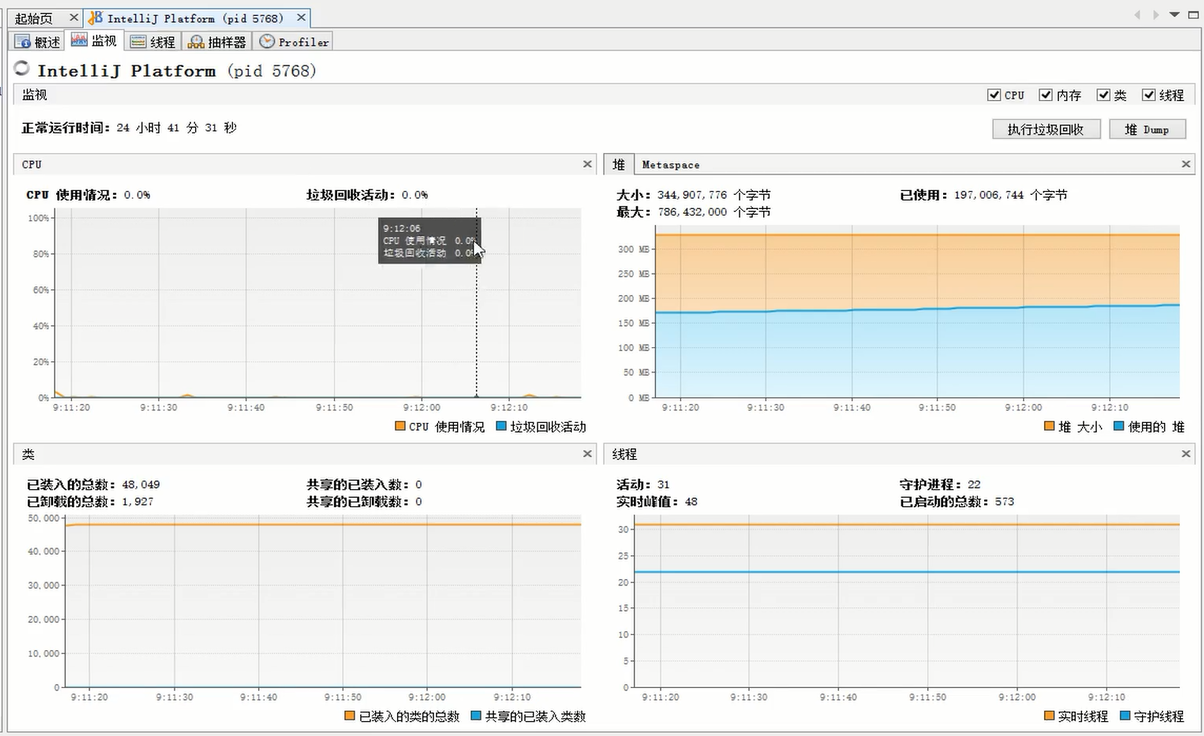
7.4、查看线程详情
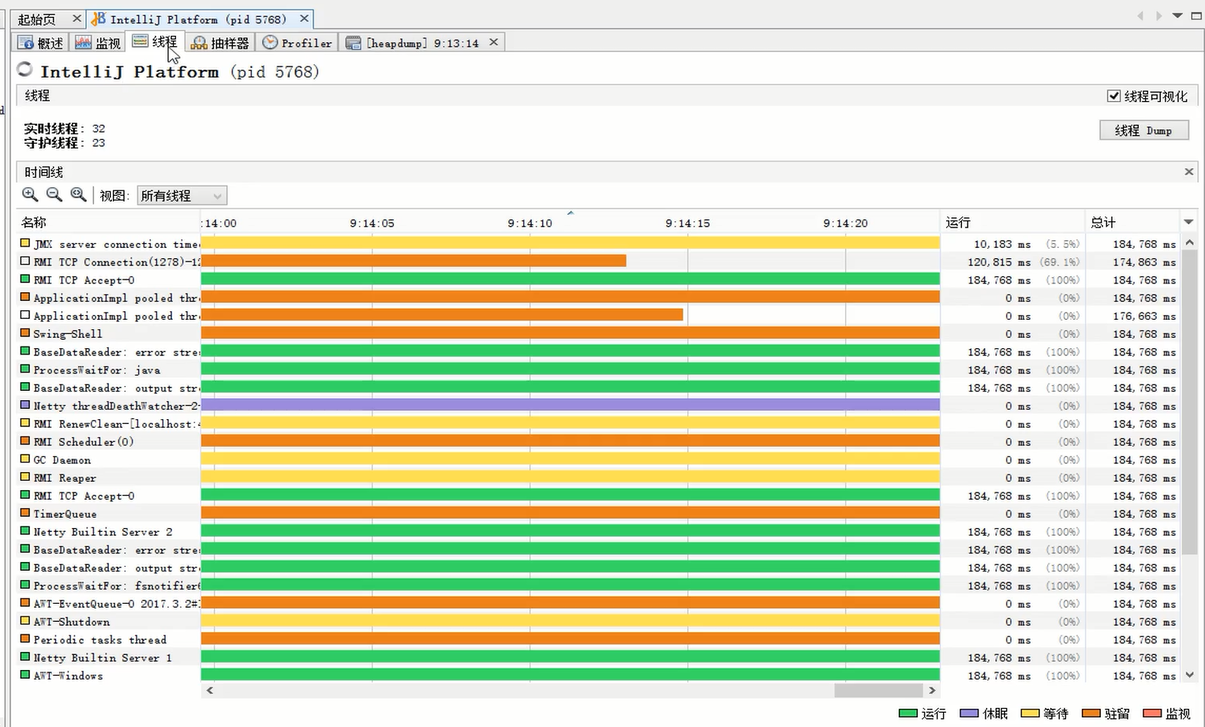
也可以点击右上角Dump按钮,将线程的信息导出,其实就是执行的jstack命令。
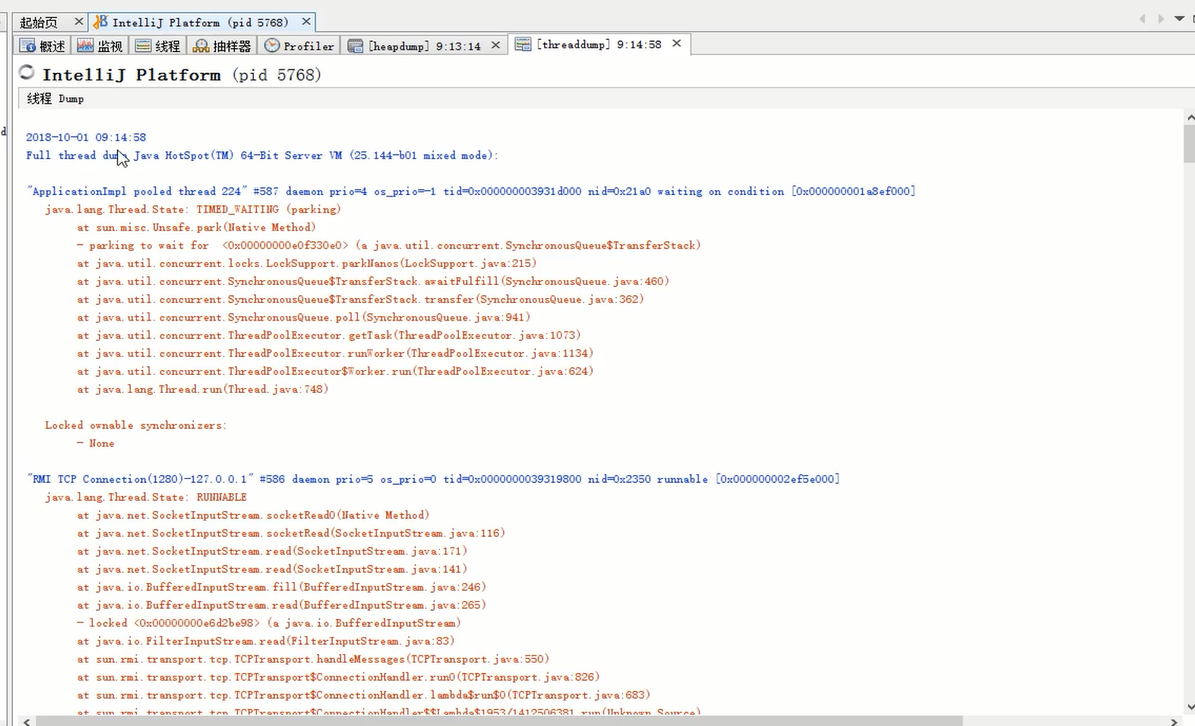
发现,显示的内容是一样的。
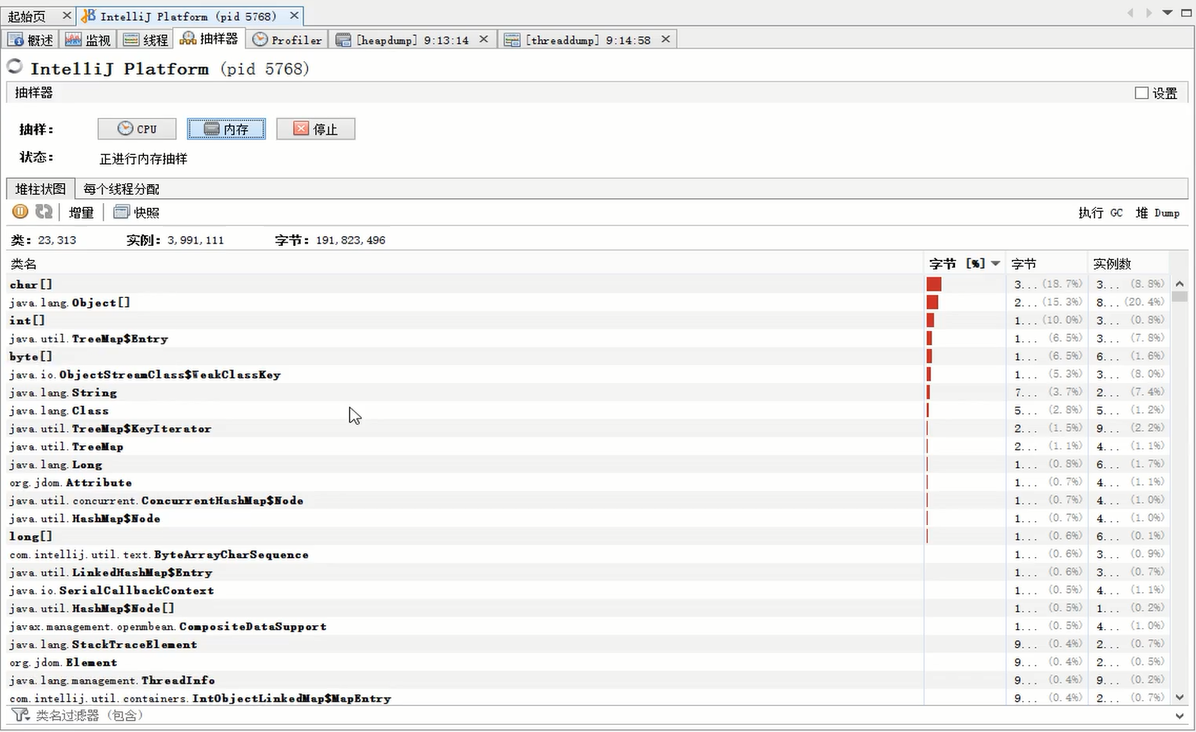
7.5、抽样器
抽样器可以对CPU、内存在一段时间内进行抽样,以供分析。
7.6、监控远程的jvm
VisualJVM不仅是可以监控本地jvm进程,还可以监控远程的jvm进程,需要借助于JMX技术实现。
7.6.1、什么是JMX?
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。
7.6.2、监控远程的tomcat
想要监控远程的tomcat,就需要在远程的tomcat进行对JMX配置,方法如下:
1 | #在tomcat的bin目录下,修改catalina.sh,添加如下的参数 |
保存退出,重启tomcat。
7.6.3、使用VisualJVM连接远程tomcat
添加远程主机:
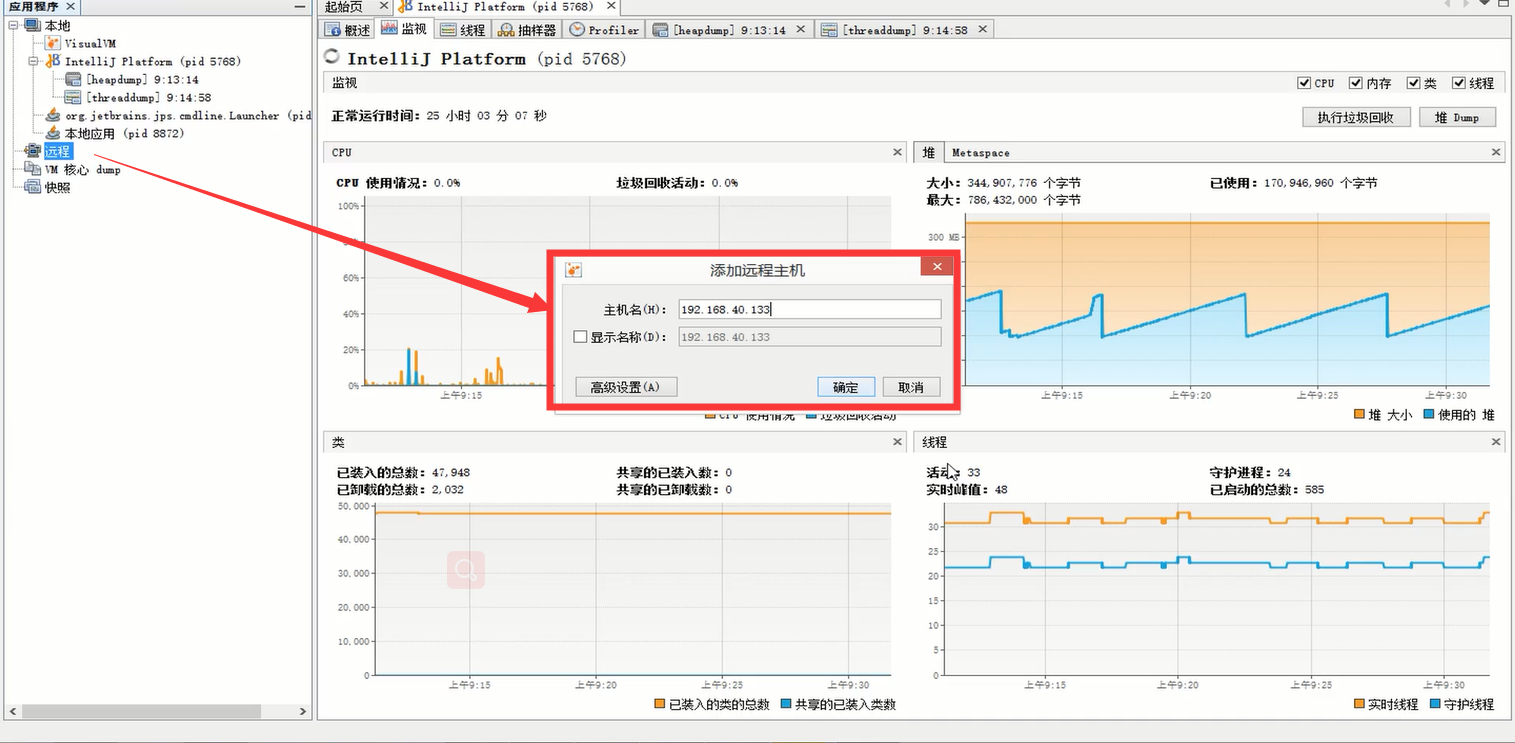
在一个主机下可能会有很多的jvm需要监控,所以接下来要在该主机上添加需要监控的 jvm:
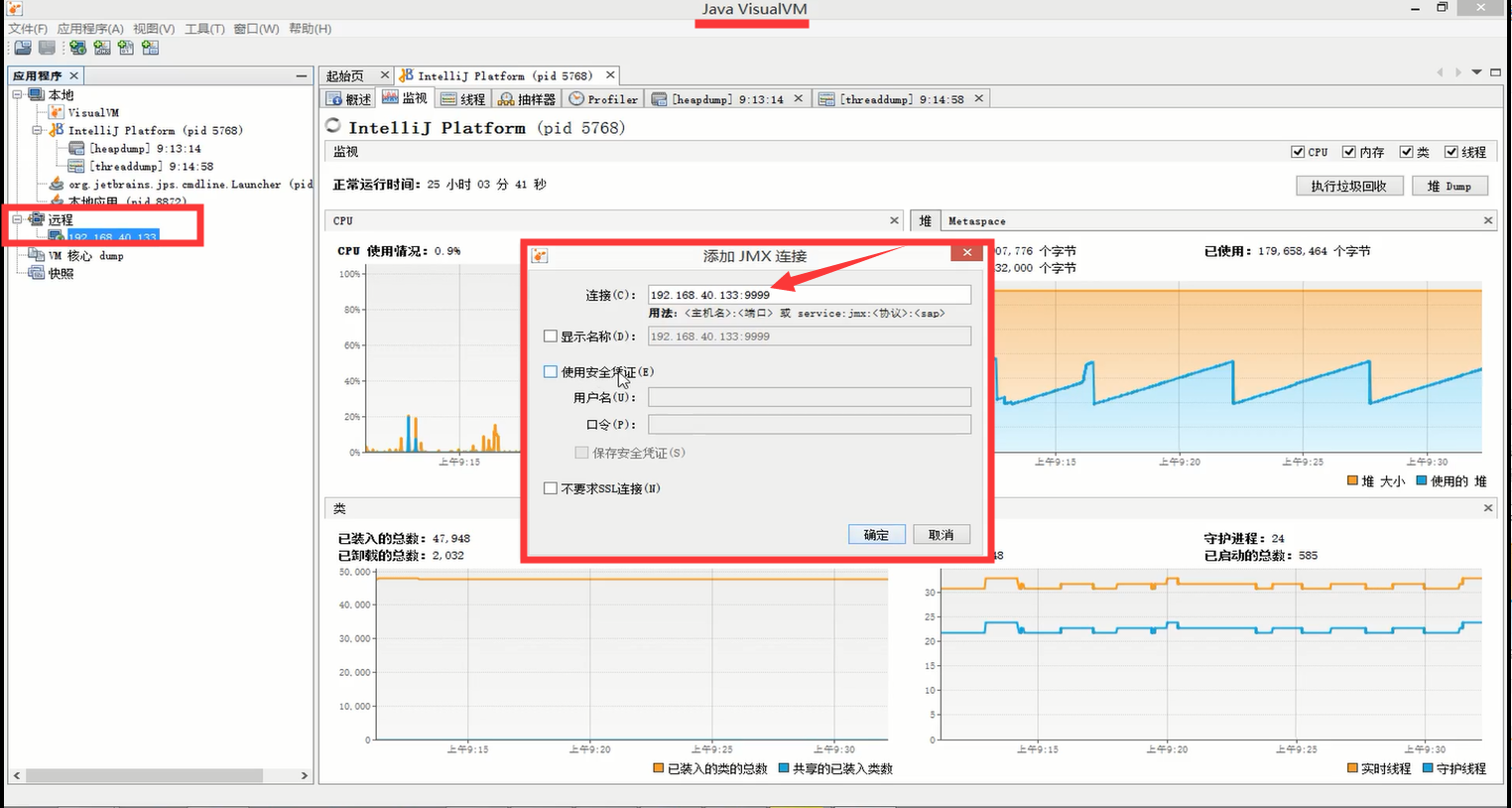
图片中的9999 是前面在远程tomcat中JMX配置的远程连接端口 。
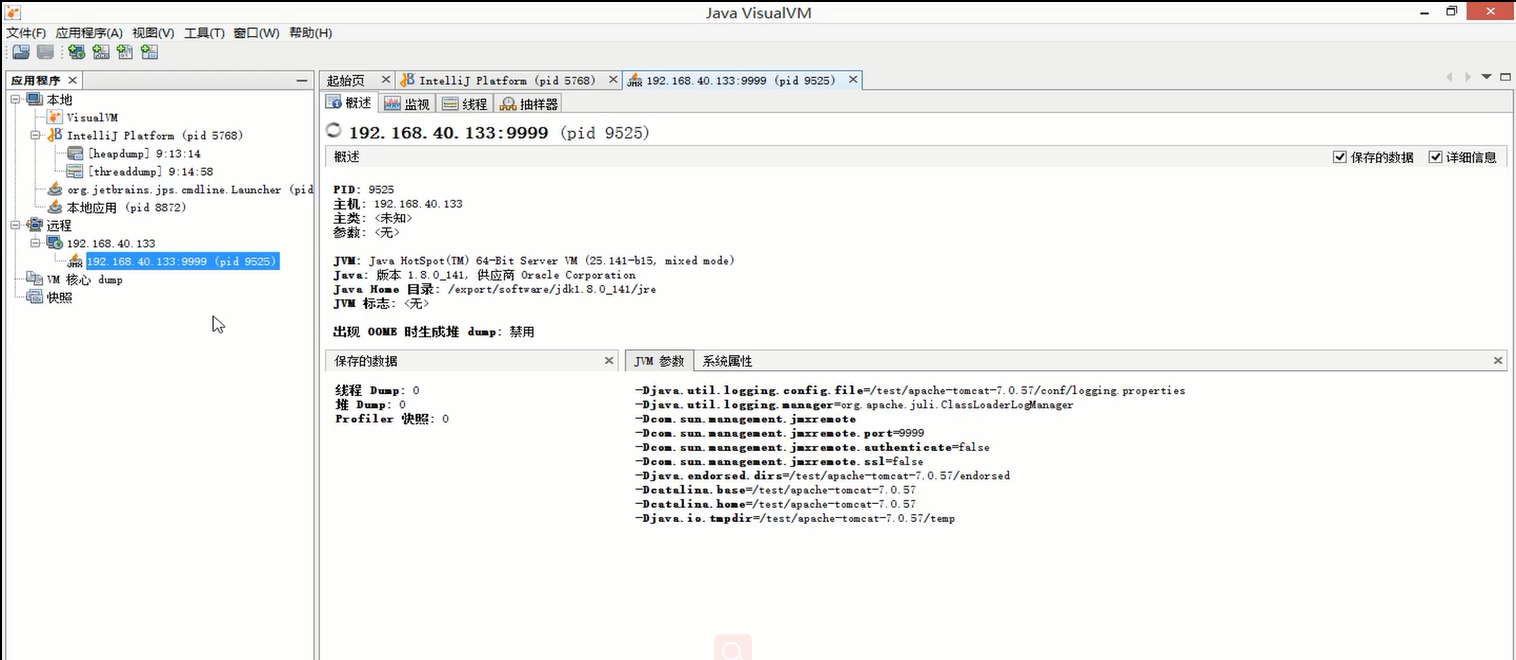
连接成功。使用方法和前面就一样了,就可以和监控本地jvm进程一样,监控远程的 tomcat进程。

