[TOC]
个性化推荐算法实践第11章排序模型总结与回顾
- model在测试数据集效果回顾
1、逻辑回归模型、gbdt模型、gbdt模型与逻辑回归混合模型以及wd模型在测试数据集上的效果进行一下简单的回顾
LTR中特征维度浅析
2、我们会对工业界实际项目中建立排序模型所使用的特征进行一下简单的浅析。
工业界Rank技术展望
3、对工业界的排序技术进行一下展望
一、model在测试数据集效果回顾
1、效果回顾
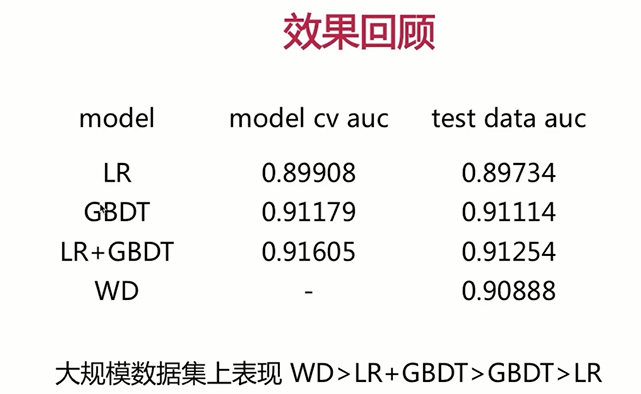
下面首先来回顾一下各模型在测试数据集上的表现。由于我们各Rank模型在线上实际使用时呢是对item进行打分,然后呢不同的item按照这个得分的展现给用户,所以呢我们这里更加关心的是模型对于我们item预测得分序的关系,所以呢也就是AUC我们这里从我们模型交叉验证得到的AUC以及模型在测试数据集表现的AUC两点的进行一下回顾。
我们在排序部分的重点介绍了四种模型分别是逻辑回归、GBDT、GBDT与逻辑回归的混合模型以及我们基于深度学习的WD模型。
首先呢从我们的模型交叉验证的效果来看一下GBDT与逻辑回归的混合模型的表现要好于GBDT。GBDT要好于我们的逻辑回归模型,由于我们的WD并没有采用我行交叉验证的方式呢,去评估,所以这里没有数据。好了,我们再来看一下训练好的模型呢,在测试数据集上的表现也就是看一下模型的泛化能力。这里同样的GBDT与逻辑回归的混合模型的是要好GBDT,GBDT是要比逻辑回归好,这里要注意一下,在实际的我们的项目中WD模型实际上是表现的最好,但是在这里限于我们的样本的数量了只有3万等等的一些限制。WD表现的要略低于GBDT。不过没有关系,如果大家有机会在实际项目海量的数据集当中了去实践一下,不同的Rank模型的话,大家一定能得到下面的结论,WD模型的表现是要好于GBDT与逻辑回归的混合模型。混合模型是要好于GBDT模型。GBDT是要好于我们的逻辑回归模型。但我实际工作中零一搭建个性化排序系统时得到的结论也是这样的。
2、离线评估
模型交叉验证(model cv)
在我们训练不同的排序模型,将不同的模型放到线上时,我们如何来评价离线的准入以及在线的收益呢?下面来看一下排序模型的评估,首先来看一下离线评估,第一点的,我们需要看一下模型交叉验证得到的指标,这些指标的,包括我们课上重点提到的AUC,以及准确召回等等的一些指标,这些指标我们需要明确它的物理意义,这样才能够帮助我们清晰地判断模型的效果。
model test data performance
最终的我们还需要判断一下模型的泛化能力,也就是模型在测试数据集上的表现,比如模型在测试数据集上得到的AUC,得到的准确率等等,我们结合着不同的业务场景的也会有一些独自的评判标准,比如我们在信息流场景当中呢,我们可能更关注的是session的平均点击位置,这里简单的解释一下。我们每一个session展示了,比如说三条数据。
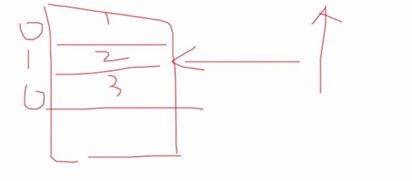
在我们的测试数据上的原有的情况下,比如我们点击了这3条,经过我们训练模型对于这三个数据得重新打分之后呢,我们能否将已经击的这个第二条呢?学习到第一的位置,这样我们的平均点击位置的就更靠前了,这样的效果也就说明了是更好的。当然了,不同的业务场景还有一些其他的指标。
3、在线评估
业务指标
下面我们来看一下在线指标,首先呢是业务指标。比如说点击率,购买率,平均阅读时长,总的交易额度等等,我们根据不同的业务场景的制订了评价的指标,最终的结果呢也已在线AB测试得到的业务指标的生效为准。
平均点击位置
离线的评价指标的只是我们能否准入的一个衡量的标准,并不能决定我们在线实际效果的好坏,当然了这里还有一些辅助的评价指标,比如像之前我们介绍的平均点击位置。当然呢在线评估时,我们首先来看一下业务指标,其次呢是我们的辅助评价指标。好啦,在线离线的评估呢,我们已经说完了。
二、LTR中特征维度浅析
1、特征维度
- 特征维度
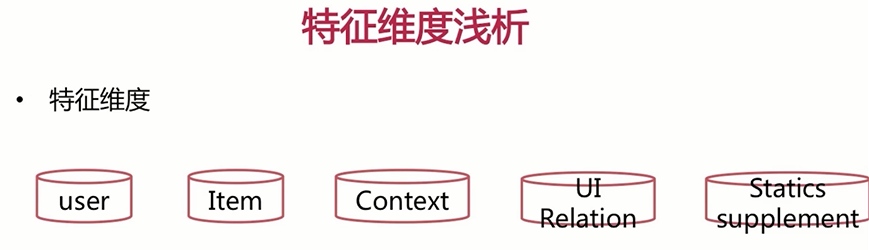
下面来看一下特征了有哪一些?我们的构建排序模型是常用的特征的有以下几个方面,我们来简单的介绍一下,用户侧的特征包含了用户的静态的属性,比如说年龄,性别,地域,还有一些简单的统计特征,比如该用户在我们平台上浏览过多少个商品?点击过多少个商品的购买过多少个商品的,购买过多少个商品啊?近30天浏览了多少商品的这种长短时的统计,最后还有一些用户侧的高维的特征,我们基于它的浏览点击购买历史的给他打上一些标签,比如说呢,她就喜欢某某品牌的香水某某品牌的鞋子等等。刚刚介绍用户特征侧时是以电商场景举例。对于其他的产品道理也是一样的,比如说信息流。我们只需要统计一下用户发现喜欢财经呢,还是喜欢体育,是喜欢娱乐呢?还是喜欢科技,甚至呢我们还可以给他打上标签儿,是科比的标签的还是鹿晗的标签等等?道理都是一样的。
商品侧的特征基础的特征包含商品的名称,商品的上线日期啊等等统计的特征的包含商品被购买的次数。商品的点击率呀,商品的购买率啊等等。一些高维的标签,那比如说这个商品的,他是深受90后欢迎啊,深受年轻女性的欢迎啊,我们的上下文的特征的有,当前是星期几呀?现在是几点呀?用户请求我们服务时所处的地理位置信息等等。用户和item的关系。比如说这个商品呢,是该用户两个月之前加入到购物车里头,一个月之前点击过的呀,半年之前购买过呀,等等的一些信息,还有我们的统计登录信息,比如说呢商品的上架的时间呢与购买率间的关系,比如说近一个月之内上架的商品打开的购买率是多少?近两个月等等我们统计出来显然的又增加了一维特征。好了我们曾经无数次说过特征与样本是决定我们最终这个整体表现的天花板,而我们采用不同的模型的只能去逼近这个天花板。像我刚才介绍这些不同维度特征时呢,我们是用电商场景举例的,但是呢实际的项目中呢,假如没有做过电商的场景,可以根据特征的大体由这五个维度来想到一些电商场景下应该有哪些特征?大家在自己的项目当中呢,或者自己解决实际问题过程中的,也一定要结合的实际去构造我们需要的特征。
2、特征的数目
- 特征的数目
我们说过为了防止过拟合,那我们尽量要将特征与样本的数目来维持在1:100。举例,比如说我们这里有1000个训练样本,那么这里我选择了十个特征,这是没有问题的,但是呢,有的同学说我没有找到十个特征,我只找到了八个那也是没有问题的。
可能最终我们学习出来的效果不会很好。但是有的同学说我找到了50个特征,那么显然呢,这个模型呢就会过拟合。他在测试数据集上的表现的就会比较差,就是说它的泛化能力就不会很强。
三、工业界Rank技术展望
1、多目标学习
我们知道了在信息流场景中的我们既想用户拿多点击,也就是点击率预估模型也想用户停留的阅读时长的要长一点。这样呢就是两个目标。之前的可能有很多方式呢,比如说训练两个模型,一个呢是点击率预估模型,一个是平均阅读时长预估模型,然后乘起来,比如说那像电商场景中的我们既想用户呢,他得购买率也就是说最终的转化率呢要高又想拿我们懂得交易额度也能高。有人呢对这种多目标问题的提出了一种将不同的目标的融合到一个网络里进行学习的方法。
2、强化学习
我们知道强化学习的是成功保证历史最大回报率的一种办法,现在呢这种算法呢,在游戏里应用的比较广泛也比较成熟,但排序的领域也有一些落地与尝试。希望大家的能够对这些较新的技术进行不断的追求,不断的学习。不断的探究,不断的尝试。那么本章节的内容到这里就全部结束了,本章节的重点是对之前多讲述过的排序部分的内容进行了总结回顾,下一章节我们将会对个性化推荐算法课程的内容来进行一下总结。

