[TOC]
个性化推荐算法实践第08章浅层排序模型逻辑回归
本章节重点介绍点击率预估模型,逻辑回归模型,以及选取实例数据集,从特征选择到模型训练、模型评估等几个方面来代码实战逻辑回归模型。
本章节重点介绍一种排序模型,逻辑回归模型。从逻辑回归模型的背景知识与数学原理进行介绍。并介绍样本选择与特征选择相关知识。最后结合公开数据集。代码实战训练可用的逻辑回归模型。
逻辑回归模型的背景介绍
一、LR(logistic regression逻辑回归)背景知识介绍
将会介绍什么是点击率预估、什么是分类模型以及LR模型的基本使用流程、LR模型的基本训练流程,从这几个方面介绍LR的背景知识。
1. 点击率预估与分类模型
什么是点击率预估呢?
相信点击率的概念大家都知道,在系统中,点击率 = 点击的数目 / 总展现的数目,而点击率预估就是针对特定的用户在当前上下文结合用户当前的特征给出的item可能被点击的概率,预估方法可以是一些简单的规则也可以是使用模型,目的就是得到不同的item在此时应该被展现的顺序关系。
点击率预估在推荐、搜索、广告领域都被广泛使用。
那么什么是分类模型呢?
用一个简单的例子进行讲解:假如去菜市场买牛肉,这个牛肉可以称之为新鲜或者不新鲜,我们之前的判断就是根据这个肉的时间。假如有一个模型可以再牛肉到来的时候就给出标签,是新鲜或者不新鲜,那么这样的一个模型就是一个分类模型,而且是一个二分类,因为这里的label只有新鲜或者不新鲜。
当然,这个分类模型也可以是多分类,如果说这个label有很多个,那么便是多分类。我们这里讲的点击率预估实际也是一个二分类问题,因为,点了样本就是1,没点就是0。就在这两类之间,我们会给出每一个样本预估出它倾向1的概率,基于次概率的大小决定了此item的展现顺序。
2. 什么是LR?
假设二维空间中有一些数据点,我们想用一条直线来拟合这些数据点经过的路径,这便是回归。但是,LR是一个分类模型,需要在样本进入模型之后给出分类标签。
所以LR对于回归得到的数值会进行一个处理,使之变成0,1这样的标签。这个梳理就是将得到的数值输入到一个函数中,这个函数就是单位阶跃函数,后面会详细讲解这个函数。
这里说的二维空间是只有一个特征的,用在之前讲解的牛肉是不是新鲜这个案例里,这个特征就是时间。那么如果扩展到三维空间中,可以再加入一个特征,比如说这个牛肉的含水量。那么这个时候,可能就不是用一条直线,而是用一个面来拟合整体样本经过的路径。
3. sigmoid函数:单位阶跃函数
这个函数有一个特点,那就是输入为0的时候,值为0.5,但是输入>0 的部分,很快便逼近于1,输入 < 0 的部分,很快便逼近于0,所以称之为阶跃函数。
这样的函数,很少有在中间的部分,所以可以很容易的分辨出是1还是0,正好符合0、1分类模型的要求。
4. LR模型的工作流程
前面介绍过LR模型的主体流程是:首先对数据进行一个拟合,不管是二维空间里 y = k x + b 这样的直线,还是三维空间里y = a1 x1 + b2 x2 + c 这样的平面,亦或是更高维度我们需要学习更多的参数。像y = k x + b 中的k、b,像三维空间里我们用平面 y = a1 x1 + b2 x2 + c 这里面的a1、b2、c这样的参数都是我们需要学习的。学习完这些参数之后,也就得到了模型。得到模型之后,用参数与输入的特征进行相乘,同时将得到的数值放入前面介绍过的单位阶跃函数中得到类别。
下面用具体的例子,详细介绍一下具体的工作流程:
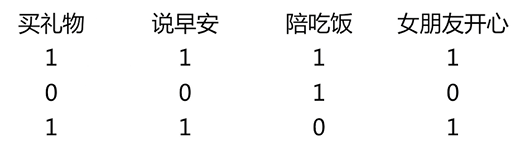
这里是三个训练数据,训练数据的label就是女朋友是不是开心。我们看到这是一个二分类问题,女朋友开心,label就是1;女朋友不开心,那么label就是0。同时这里每一个训练样本都有三个特征,分别是买礼物、说早安、陪吃饭。
样本1 是买了礼物,说了早安,陪了吃饭,那么女朋友是开心的。
样本2 是没有买礼物,没有说早安,陪了吃饭,女朋友是不开心的。
样本3 是买了礼物,说了早安,,没有陪吃饭,女朋友是开心的。
这里的目标是通过这三个样本,学习出一个LR的模型,然后能够通过这个模型,帮助我们预测女朋友是否开心。我们需要学习的参数是什么呢?很明显就是 a x1 + b x2 + c * x3,这里的a、b、c这三个参数,在得到了这三个参数之后,在接下来的某一天,我们将买没买礼物,说没说早安,有没有陪吃饭带入到这个公式中,也便能够自己知道女朋友是否开心。
以上就是LR模型的工作流程
5. LR模型的整体训练流程
(1)从log中获取训练样本与特征
在工业界中,样本与特征都不会是处理好的,我们需要自己从日志中,根据需要去提取。比如在推荐系统中,我们可能有展示日志,有点击日志,有基于点击统计User Profile,也有入库时就获得的item info信息。首先,我们需要判断,哪些展现,哪些点击是需要的,也就是样本选择。因为,有很多样本含有脏数据,我们需要去除掉。
其次,我们需要判断我们需要的是用户的哪些特征。比如说用户的年龄、性别,或者是item的哪些特征,比如item的种类、item的title、item的时长等等。这就是特征选择。
(2)模型的参数学习
获取了样本与特征之后,需要决定模型学习的学习率,是否正则化,以及选用哪一种正则化的方式,同样还有学习的方法等等参数设定。
得到了模型之后,同样需要进行离线评估。
这里面包含了模型本身的指标,还有模型应用到测试集中的指标,来看一下我们的模型是否可用。如果模型可用,需要将模型实例化。
(3)模型预测
这里的预测包含可能是将已经实例化的模型录入到内存中提供服务,也可能是基于已经实例化好的模型再搭建一个模型的服务。
预测部分需要将待预测的数据集带入到训练格式去抽取特征,抽取完特征的待预测的样本放入到模型中便能得到预测的结果。
6. LR模型的优缺点
优点:易于理解,计算代价小
这个易于理解是指,我们在建模过程中我们把则认为对结果又影响的特征罗列出来就可以,比如说我们认为哪些因素会影响女朋友开心或不开心呢,那就是买没买礼物,说没说早安,有没有陪吃饭,有没有送回寝室…然后学习这些因素的权重就可以。
在推荐系统中,我们预估这个item能不能被user点击。同样也可以选取一些关键的特征,比如说item的历史点击率,item所属的类型,然后用户喜欢看的类型,这个item的长度等等。
由于LR模型是一个浅层模型,而且需要学习的参数的数目与特征的维度是一一对应的,比如说有100维的特征,那么就需要学习100个参数,所以计算代价是比较小的。
缺点:容易欠拟合,需要特征工程来补足模型容易欠拟合的缺点
欠拟合是一个专业术语,解释一下:
欠拟合表示模型没有从训练数据中学习到所有的规律。我们以女朋友是否开心为例,比如说陪吃饭,以及买礼物都不能单独的影响女朋友是否开心,也许这里需要一个交叉特征,比如陪吃饭和买礼物放在一起的一个特征。当这两样同时做了,女朋友才会开心,如果没做或者是只做了一样,女朋友都是不会开心的。
那么在这种情况下,我们发现,由于LR不能主动的去想学习这些交叉特征,所以需要我们大量的构造特征。这也就是说,特征工程来补足模型容易欠拟合的缺点。
二、LR算法数学原理解析
将会介绍LR模型的函数表达式、损失函数以及梯度,并且介绍什么是正则化。(LR模型参数迭代的数学原理)
逻辑回归模型的数学原理
1、单位阶跃函数(sigmoid)
单位阶跃函数及其导数
单位阶跃函数的函数表达式:
当 x = 0 时,f(x) = 0.5 ; 当 x = 10 时,f(x) 接近于1 ,这也就是之前说过的,当x > 0 的时候,会非常快速的接近于1 ;当x < 0 的时候,会非常快速的接近于0 。这完全符合LR模型,对0-1分类时的要求。
下面再来看一下单位阶跃函数的导数:
经过简单转换,上述式子转换为:
也就是 f(x) 的导数 = f(x) * (1 - f(x))
2、LR模型的函数表达式
LR模型分为两个步骤:
- 拟合数据点;
公式:
这里的w1,w2…是需要学习的参数,这里的x1,x2…是选取的特征。
用上一部分中的例子来分析,x1可能是陪吃饭,x2可能是送礼物等。
- 将第一步回归得到的数值带入到阶跃函数中,进而得到分类。
也就是女朋友是否开心的倾向性,或者说item是否被用户点击的倾向性。
LR模型的函数表达式就介绍到这里,之前介绍个性化召回算法LFM的时候,曾经介绍过一种最优化的方法来学习参数—梯度下降。
梯度下降需要首先设定损失函数,进而得到梯度,完成参数的迭代。
下面看一下LR模型的损失函数。
3、LR模型的损失函数
这个损失函数采用的是log损失函数,与之前介绍word2vec算法的损失函数是一致的。
这里没有用平方损失函数的原因是:这里LR模型需要两个步骤,第二步是将第一步拟合的值带入到单位阶跃函数中,如果此时使用平方损失函数的话,损失函数并不是下凸的,而且有很多个波谷,我们在梯度下降的过程中,很容易学习到并不是最低点的波谷,也就是不能学习到最小化的loss function。所以这里采用log 损失函数。
下面解释一下公式:
i :样本的数目。也就是说这里有n个样本。那么对于第1个样本呢,该模型下希望预测的概率最准。
p:概率,也就是本来是1的label,希望也是1;如果是0,预测成0
为了统一得到最大化的概率,当label是0的时候,我们就预测(1-这个条件概率),那么整体对于这个损失函数,我们直接最大化这个损失函数,便能够将参数学习到。
下面看一下条件概率:
这个条件概率就是刚才解释过的,如果这里y = 0,我们看到是后面这一部分起作用,那么也就是我们说的来预测(1-这个概率)。这里的w就是上一篇文章介绍的LR函数表达式的第一部分,也就是所有的参数与特征相乘得到的结果。
下面看一下,将条件概率带入到损失函数中,得到的:
来看单一样本,这里不再关心 n 个样本。
我们来看单一样本,单一样本这里我们知道$h_{w}\left(x_{i}\right)^{y_{i}}$被log一下,$y^i$是可以提到前面去的;同时,相乘被log一下就变成了相加,就得到了上面式子。
之前说过,loss函数需要最大化,那么这里加了一个负号,所以上面式子中的 loss 需要最小化,也就是使用梯度下降法就可以。
这里再次重申,这里$x_i$表示,第 i 个样本对应的所有特征;这里$y_i$ 是第 i 个样本对应的label。如果想表示第 i 个样本的第一个特征,会在$x_i$的右上角标明$x_{i}^1$,以示区分。
4、梯度
下面看一下loss损失函数对于参数w的梯度:
首先,这里选取参数的某一个,这里选择特征$x_j$对应的参数$w_j$来进行演示求偏导,这里应用链导法则(也便等于loss函数对于LR模型输出的偏导):
这里$h_{w}\left(x_{i}\right)$表示:第 i 个样本的输入到 LR 模型中,我们给出的输出。它的公式是$f(x)=\frac{1}{1+\exp (-w)}$。这里的W表示为$w=w_{1} \times x_{1}+w_{2} \times x_{2}+\ldots+w_{n} \times x_{n}$,那么这里$\frac{\partial w}{\partial w_{j}}$就是$x_j$。也就是第i个样本的第j维度的特征。
损失函数
损失函数求导
看一下第一部分:
看一下剩余部分:
根据sigmod阶跃函数f(x) 的导数 = f(x) * (1 - f(x))。$\frac{\partial w}{\partial w_{j}}$就是$x_{i}^j$。
带入梯度公式,得到:
那么 i 样本对应的梯度已经得到了,如果这里有n个样本的话。同理,对每一个样本求得梯度,然后去 1/n ,就得到了平均梯度。
得到平均梯度之后,用梯度下降对这一维度的特征进行更新:
当然,要对所有维度的特征都进行更新,即w1, w2…同样也是按照这种方式来进行更新迭代的,这里$\alpha$是指学习率。
四、正则化
- 什么是过拟合?
过拟合就是模型对于训练数据过分的学习,对训练数据完美的适配。有时候训练数据并不能反应事情的本质。
eg.也许女朋友不开心是因为考试挂科了,假如给与我们的训练数据中,全都没有挂科,那么我们后面如何买礼物,如何陪吃饭,我们都会发现,女朋友都会不开心。我们便无法学习到真正事物的本质。也就是我们所说的泛化能力减弱。
完全为防止过拟合,就提出了正则化的概念。
常用的正则化方法有两种:L1、L2
首先看一下L1正则化的公式:
L1正则化的公式,是在原来的损失函数的基础上,将所有权值的绝对值求和,这种方式下,使模型的参数变得稀疏,会产生一部分为0的参数。物理意义上说,就是起作用的特征变少了,模型变得简单了。这样也就不容易过拟合了。
下面看一下L2正则化的公式:
是在原来损失函数的基础上,加上每一个权重的平方和。因为要最小化损失函数,所以这里倾向于将每一个权重学的比较小。试想一下,如果某一个权重比较大的话,面对数据分布变化的特质数据会产生结果上的非常大的扰动。这也不利于模型的泛化能力。$\alpha$是指正则化参数。
三、样本选择与特征构建
将会介绍模型训练中非常重要的一步,那就是样本的选择、特征的选择与处理。
我们知道样本与特征决定了模型表现的天花板,而选择什么样的模型只是来逼近这个天花板。
回忆一下,8-1中给出的实例,当时用了3个样本,3个特征来演示LR模型的工作原理。但是,可能会有疑问,为什么只有3个样本?在实际的项目中,可能会有非常多的样本,其中有些样本是可以用的,有些样本是不可以用的,到底哪些可以用,哪些不可以用。包括我们有很多的特征,依据什么规则来判断是否对最终的结果有效都是下面要介绍的内容。
3.1、样本选择
下面首先看一下样本方面的知识。
在点击率预估过程中,需要的样本是带有label的,也就是点击或者未点击,这是大前提。也就是说,每个用户的每次刷新,我们都能对应上item是否被点击。这么多的样本都是我们训练时候的有效样本么?
当然不是!
下面首先看一下样本的选择规则。
1、样本选择规则
这里面主要包含两个因素,1. 采样比例; 2. 采样率。
①采样比例
正负样本需要维持一个正常的比例,正常的比例需要符合产品的实际形式。比如说某个产品,用户三次到来就会产生一次购买,那么我们的正负样本就是1:2的比例。
当然,模型训练还有很多的采样规则,比如说在某些模型训练的时候,我们需要确保userid的样本达到平均水平,比如说最少要20个。这个时候,就需要做样本增强。对于该userid下的样本,我们需要给他一个特定的权重,来确保它虽然样本少,但是也能达到最低要求。
②采样率
当模型没有办法用所有的训练数据的时候,必须设定一定的采样率。常用的随机采样的方法就是其中的一种。
2、样本过滤规则
样本过滤规则有两个大方面:
- 结合业务情况
比如在样本选取时,需要去除爬虫带来的虚假请求,测试人员构造的测试 id 数据,作弊数据等等。还需要根据特定场景下模型的目标来保证样本选取的有效性。
- 异常点的过滤
常用的方法有基于统计的方法。举个例子,比如说,某个特征,就以某item被评论的数目这个特征为例,99%的评论数目都均匀的分布在0-5000之间,而top 1% 有几十万、几百万这种数量级的评分。对于这种数据,我们选取一个阈值,大于这个阈值的直接去掉,为什么呢?因为这会给我们在特征归一化的过程中,造成极大的样本分布不均。
还有就是基于距离的方法。比如说,某一样本数据与其余样本点的之间的距离,有80%都超过了我们所设定的阈值,这个样本就需要被过滤掉。
3.例子
下面以具体的实例来说明如何选取有效的数据来保证模型训练的目标。
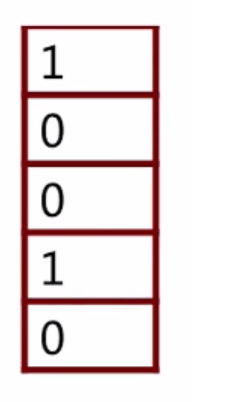
这是某个推荐系统展现给用户的推荐列表,用户依次看到的是itemid1 、itemid2 ….itemid5,同时用户对着5个item分别做了不同的处理,用户点击了itemid1和itemid4,并没有点击itemid2、itemid3、itemid5。这时,我们在构建训练样本的时候,是不是这5个样本都需要呢?
答案是否定的。
这里我们只需要前四个。为什么不要第5个呢?下面解释一下原因呢:
我们模型的最终学习目的是希望用户能够在最开始的位置发生点击,而不用下拉。所以,目标是将最终的推荐列表学习成1,1,0,0,0的形式。在这里我们发现,逆序对是0,0,然后1。对于最后的这个0,我们有两方面的原因不选择它作为训练样本,第一方面,我们不能确定用户是否真的看到了这个数据,对于以上的4条,我们可以确定用户真的看到了,因为最后的点击发生在第四条,用户想要点击到第4条,就需要下拉看到第4条数据;第二个原因,是因为这个数据对我们学习的目标是没有帮助的,如果选取还会增加负样本所占的比例。
结合刚才的分析,最终在这一次展现当中,我们得到了4条样本。

他们分别是位于位置1、位置2、位置3、位置4的样本,我们对每一条样本选取了一些特征,打上label。同时并没有选取位置5的数据。
3.2、特征方面
首先对特征进行一个概述,特征如果按照数值类型可以分为连续值类型和离散值类型。举个例子,连续值类型,像item的平均观看时长可能是3.75分钟,4.28分钟等等。所以说,是不可穷举的。而离散值类型是可以穷举的,比如说某人的学历,就是小学、初中、高中、大学、研究生、博士等。
同样,按照统计的力度同样可以分为低纬度和高纬度,低纬度的特征包含像人的年龄、性别,高纬度的特征像这个人他过去30天喜欢什么样的电影,这个人历史上喜欢什么类型的电影等等。
根据数值变化的幅度,可以将特征分为稳定特征和动态特征,稳定特征就想item的历史点击率,而动态特征就想item的天级别的点击率。
特征的概述就概述到这里。
下面看一下如何做特征选择。
1. 特征的统计和分析
首先需要知道特征的获取难度,比如说,我们想使用用户的年龄和性别这两个特征,我们发现用户画像中并没有这两个维度。如果需要的话,我们需要根据用户的行为建立一个模型,预估这两个特征。显然成本是较大的,就需要放弃。
第二个是需要看一下覆盖率,同样是用户的年龄和性别这两个特征进行举例。如果说发现能够获取到,但是在整体的覆盖率上不足1%,我们也是不能够用的。
下一个就是特征的准确率,我们发现视频的平均播放时长都只有几毫秒,显然这是违背常识的,那么这个特征也是不能够使用的。
在我们初步分析了哪些特征可以使用之后,我们到底选取什么样的特征来完成训练呢?
2. 特征的选择
主要分为两个大方面:
(1)根据自己的建模常识,也就是说我们想预估一个目标的话,我们知道哪些特征与这个目标是紧密相连的。比如我们想预估这个item的点击率,那么很明显这个item的类别与这个用户喜欢观看的类别是强相关的特征。还有一些强相关的特征,比如这个item的历史点击率,在我们初步根据自己的常识选取了这么多的特征之后,我们训练出了第一版的模型。
(2)那么剩下的特征选择第二步就是基于模型的表现。我们训练完了基线版的模型之后,如果不能够满足我们对于目标的需要的话,我们应该不停的增减特征来发现增减特征对模型指标的影响。如果说减掉某个特征,反而指标变好的话,那么很明显这个特征就不应该是我们需要的。
实际上,在我们选定了特征之后,想要让模型能够识别这些特征,我们需要将特征变成数字。这也就是特征的预处理。
3. 特征的预处理
特征的预处理往往包含三大步骤:
(1)缺省值的填充
缺省值是指某些样本里的某些特征是缺失的,我们应该用什么样的规则来填充呢?
业界常用的规则有:使用这个特征的众数,或者是平均数来填充。
(2)归一化
归一化是指将不同维度的数值特征都转化到0,1之间,这样有利于减少由于不同特征绝对数值的影响,对模型权重的影响。举个例子:比如说有一个特征是收入,这个收入可能是几千几万的大数据;还有一个特征是工作的时长,这个工作的时长可能每周都在40-60小时之间,这样可以发现数量值是不一样的。我们需要将他们归一化,这个归一化可以使用排序归一化,以及最大值归一化等等。
排序归一化是指:这一维度的特征按数字进行排序,排序最大的数字将变成1,排序最小的数字变成0。那么举一个例子:如果说一共有10个样本,那么这10个样本之间进行了排序,按照数字的大小,显然最小的对应0.1,第二小的对应0.2,依次类推,最大的变成了1,这样就归一化了0-1之间。如果样本的数目更大,就依此类推。
最大值归一化是指:我们统计出这一维度特征的最大值,然后让所有数字都除以这个最大值,显然这一维度的特征就会被归一化到0-1之间。
(3)离散化
特征的离散化并不是所有模型都需要的,但是逻辑回归LR模型是需要的。
下面以具体的例子讲解什么是离散化:
首先以一个连续值举例,这个值表示人平均每周工作的时长,这个人每周工作23小时,我们怎么离散化呢?

首先需要统计一下,我们样本当中这一维度特征的分布,比如我们想四段离散化,这里我们就需要统计一下四分之一分位点。这里就是0-18小时是一个区间,18-25小时是一个区间,25-40小时是一个区间,40-无穷大是另一个区间。那么我们总共有4个区间,这4个区间我们发现23是位于18-25这个区间,那么就离散化成了 [0,1,0,0]。如果这个值不是23,而是60,显然特征就会被离散化成[0,0,0,1]。当然,这里也可以不被4段化,而是5段,我们只需要按相应的去统计就可以了。
下面再以一个离散值来举例,如果说一个人的国家是中国,系统中只有三个国家,那中国对应的实例化特征就是[1,0,0],美国便是[0,1,0]。

四、代码实战LR之样本选择
1 |

